Commons:Village pump/Archive/2020/06
 | This is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |
Request for additional translation tweak: History merging and splitting
Please tweak for translation at Commons:History merging and splitting, one section title as well as buttons and the instruction following it。Tried but did not work as on enwiki:
- section title: Current requests
- buttons: View, Edit, Add topic
- instruction: See also categories: Media requiring a split up and Requested merges.
--Omotecho (talk) 01:18, 4 June 2020 (UTC)
- I for now reverted your edits. You broke the page and damaged a template entry by another user. — Speravir – 21:20, 5 June 2020 (UTC)
- For me the buttons are translated. Do you miss Japanese translations, Omotecho? Then they are to be added in Translatewiki. But a quick search showed they are there already existing. For the “See also categories” a Japanese subtemplate page for Template:Cat see also is missing, i.e. Template:Cat see also/i18n/ja. Then there would only be the one section “Current requests”. I do not know, how to deal with this without {{LangSwitch}}. This should be asked at the translators' noticeboard. — Speravir – 21:42, 5 June 2020 (UTC)
- Appreciate very much of your clarification and taking extra steps to explore the cause. I would bring the issue to translators’ noticeboard, after seeing how Template:Cat see also could be made into /i18n/ja, maybe at local Village Pump/ja. You are so kind to add the second comment, thank you. Arigatow, Omotecho (talk) 01:43, 6 June 2020 (UTC)
- Speravir, among two issues, one is solved and I wish the other would be granted further advice.
- I translated the _tl:Cat see also_ into ja, and coming back to the page, _:c:History merging and splitting_, section title shiws properly. Yey!
- Speravir, among two issues, one is solved and I wish the other would be granted further advice.
- Appreciate very much of your clarification and taking extra steps to explore the cause. I would bring the issue to translators’ noticeboard, after seeing how Template:Cat see also could be made into /i18n/ja, maybe at local Village Pump/ja. You are so kind to add the second comment, thank you. Arigatow, Omotecho (talk) 01:43, 6 June 2020 (UTC)
- I still wish to translate the section title. Small thing, but user friendly if not translators-unfriendly (~_~;). Lowering language barrier would help involve more ppl IMHO, as I wish new users will stay as Wikimedians coming to Commons per Upload drives and campaigns. Maybe I am too greedy.
- Issue with buttons: they are designated to show in Vector, aren’t they?
- It is not clear with me why it says “int:Vector-view-view” as I see the tl in source mode.
- As I’m on iPhone/iPad, I thought Minerva is the default. I copy the source from Commons:History merging and splitting/ja:
- =Current requests= <- tweak for translation pls.
- <includeonly>{{Clickable button 2 |link=Commons:History merging and splitting/Requests |text=<big>{{int:Vector-view-view}}</big> |color=green}} <!-- -->{{Clickable button 2 |link={{fullurl:Commons:History_merging_and_splitting/Requests|action=edit}} |text=<big>{{int:Vector-view-edit}}</big> |color=blue}} <!-- -->{{Clickable button 2 |link={{fullurl:Commons:History_merging_and_splitting/Requests|action=edit§ion=new}} |text=<big>{{int:Vector-action-addsection}}</big> |color=blue2}}</includeonly> :::{{cat see also|Media requiring a split up|Requested merges}}
- --Omotecho (talk) 02:17, 6 June 2020 (UTC)
- These 3 messages on the buttons
int:Vector-view-view,Vector-view-editandVector-action-addsectionhave been created for Vector skin interface, hence their names, but work in all active skins. Check Commons:History merging and splitting with: Vector (the default), Modern, Monobook, Timeless and MinervaNeue (the latter is the skin for mobile devices). There is apparently an issue with the colours, but this is not related to the translation messages. As I told you above the translations have to be done in Translatewiki, but for Japanese they exist. They are actually translated in more languages than the whole page we talk about. You must, of course, also adjust your interface language. - For the “Current requests” caption my only idea is to use the LangSwitch template, as uttered above, too. I will do this after replying here – I found this string is translated into a lot of languages in Commons:Deletion requests, so I can copy it from there.
- These 3 messages on the buttons
- — Speravir – 23:17, 6 June 2020 (UTC)
- Actually, in Commons:Deletion requests this string is not translated for all languages, but for some I found it in Commons:Categories for discussion. — Speravir – 00:52, 7 June 2020 (UTC)
Question on a forum for editorial disagreement regarding descriptions of images?
Is there a particular forum where I should raise editorial disagreement over image descriptions? Or is this the place? There's a particular image description editorial issue that I would like to have feedback on.
Thanks, WhisperToMe (talk) 20:45, 4 June 2020 (UTC)
- @WhisperToMe: I think you should discuss it on the file's talk page. --Red-back spider (talk) 20:57, 4 June 2020 (UTC)
- @WhisperToMe: The image talk page may help, but be aware that they are easily overlooked, and rarely seen: you might wait years for a response. Without particular knowledge of the file in question, better options include discussing descriptions with the uploader, fixing/clarifying errors yourself, and/or placing warning templates such as {{Inaccurate description}}, {{Fact disputed}} or {{Disputed diagram}} to give better visibility to potential errors. --Animalparty (talk) 21:56, 4 June 2020 (UTC)
- @Animalparty: @Red-back spider: I have started a discussion with the other editor (who is not the uploader). The other user may dispute me adding tags to the image description, and it's not so much a question of the accuracy of the description, but rather whether the old name of a city should be mentioned: until 1930 cities in Turkey were known by different names in English than they are now. The image in question was taken in 1920. The other editor feels the pre-1930 names should not be present in the description, while I feel they should. WhisperToMe (talk) 22:39, 4 June 2020 (UTC)
- I would probably start a discussion on the file talk page and post a message somewhere else (like here) summarizing the issue and inviting other editors to the file talk to discuss. That way the discussion is preserved somewhere future editors of that images can find it. – BMacZero (🗩) 01:49, 5 June 2020 (UTC)
In my opinion a short notice at the VP can help, especially if a discussion escalated. So, now you are here and this is obviously about File talk:İsmet Paşa Mustafa Kemal Paşa ile konuşurken (1920).jpg#Angora or Ankara. E4024 even if you maybe substantially right in this case (according to English and German Wikipedias you aren’t) I think your reaction is inappropriate, but as you should have noticed I left a reaction on the file talk page. — Speravir – 23:07, 4 June 2020 (UTC)
- @Speravir: Thank you. I think doing the English VP in these cases would be for the best. WhisperToMe (talk) 23:11, 4 June 2020 (UTC)
- @WhisperToMe: I meant the VP of Commons, the one we are at in the moment. — Speravir – 20:20, 5 June 2020 (UTC)
- Ah, I see. I meant the Commons English VP since each language on the Commons does have its own VP. WhisperToMe (talk) 20:51, 5 June 2020 (UTC)
- @WhisperToMe: I meant the VP of Commons, the one we are at in the moment. — Speravir – 20:20, 5 June 2020 (UTC)
- This section was archived on a request by: Speravir 00:12, 8 June 2020 (UTC)
Category:Cotes crispi
I've found that this category is included in Category:Cotes, which deals with a municipality in Spain. I tried to remove Category:Cotes but I can't fix it. So, please, could you help me? B25es (talk) 07:10, 7 June 2020 (UTC)
- Convenience links: Category:Cotes crispi, Category:Cotes. - Jmabel ! talk 17:04, 7 June 2020 (UTC)
- Already fixed by User:Roy17. - Jmabel ! talk 17:06, 7 June 2020 (UTC)
- This section was archived on a request by: Jmabel ! talk 17:06, 7 June 2020 (UTC)
UploadStashFileException
Today i wanted to upload a large STL file (~80MB) with the upload wizard. The upload failes with the error "Could not store upload in the stash (UploadStashFileException): "Extension is null.".". Same file was uploaded with the simple upload form without any problems. What's the problem? Morty (talk) 19:24, 2 June 2020 (UTC)
Annotations deprecated?

I went to annotate File:Old map of York, Upper Canada, 1827, Chewett, NMC16819.jpg and clicked the button to select an area of the image to annotate - or what I expected to be the button to annotate, only to find it had been replaced with a button to Open in Media Viewer
Was a decision made to deprecate annotations? Or did this happen by accident?
Was a decision made to replace the button for annotations with a button to the terrible media viewer? Geo Swan (talk) 16:31, 5 June 2020 (UTC)
- Geo Swan, I still see both buttons: big one for media viewer and smaller one above it with "Add a Note". --Jarekt (talk) 17:22, 5 June 2020 (UTC)
- Okay. between the image and the {{Information}} template I have five lines
- there is a line with links to reduced resolution versions;
- followed by a line with three links, to "original file" "request rotation" and "flash/no flash"
- the next line has the link to media viewer
- underneath that there is a link to "file information"...
- followed by a box that lets me edit captions.
- No link to annotations... Geo Swan (talk) 17:47, 5 June 2020 (UTC)
- I still have this button, as well. Geo Swan, could you check, please, whether you have the image annotator accidently disabled in your settings? — Speravir – 20:47, 5 June 2020 (UTC)
- Okay, just looked at Special:Preferences#mw-prefsection-gadgets, and the "Disable the ImageAnnotator" is definitely unchecked. This is what you wanted me to look for, correct? Geo Swan (talk) 21:22, 5 June 2020 (UTC)
- (insert:)Yes, this was the question. So, I have no clue now. — Speravir – 18:51, 6 June 2020 (UTC)
- This happens occasionally to me, usually when the browser is under heavy load. That button is added by JavaScript, and it's one of the last things done on the page. I'm not sure of the cause, but I'm sure of the symptom. - Jmabel ! talk 21:45, 5 June 2020 (UTC)
- Thanks. I do have a tendency to drive my computers to the edge of their resources. So that might be it. Cheers! Geo Swan (talk) 06:18, 7 June 2020 (UTC)
- After a reboot the button is back. Thanks Geo Swan (talk) 06:31, 7 June 2020 (UTC)
- This happens occasionally to me, usually when the browser is under heavy load. That button is added by JavaScript, and it's one of the last things done on the page. I'm not sure of the cause, but I'm sure of the symptom. - Jmabel ! talk 21:45, 5 June 2020 (UTC)
- I still have this button, as well. Geo Swan, could you check, please, whether you have the image annotator accidently disabled in your settings? — Speravir – 20:47, 5 June 2020 (UTC)
- This section was archived on a request by: Speravir 16:59, 8 June 2020 (UTC)
Getting error when trying to upoad a pdf file (same error pops up at 72%, firefox/chrome give the same result)
- Repeatedly getting a generic server error (tried like 4-5 times) when trying to upoad a pdf file (same error pops up at 72%, firefox/chrome give the same result. File can be found here https://archive.org/details/khliborobska_ukrayina_knyzhka_tretia_1921 . Any advice why I'm seeing this error? --Piznajko (talk) 05:14, 3 June 2020 (UTC)
- Did you try saving the pdf with another editor, or printing to PDF, and uploading that instead? Effeietsanders (talk) 05:31, 3 June 2020 (UTC)
- Thanks I converted to djvu and upload went through.--Piznajko (talk) 20:18, 3 June 2020 (UTC)
Before I start a DR: This template explains that we use the term "motorcycle" rather than "bike", similar to how {{Cattle}} works. But while the latter is used almost 130 times, this one is only being used only once across the whole category tree. For some reason it uses the German term "Motorräder".
- do we even need/want this?
- if we do need/want this, shouldn't it be moved to Template:Motorcycles?
Pinging creator @Gamemaster669: FYI. --El Grafo (talk) 12:26, 3 June 2020 (UTC)
- Update: same for {{Train}}, which is only used at Category:Train light trails by country → pinging @ComputerHotline: . --El Grafo (talk) 13:07, 3 June 2020 (UTC)
- If not deleted Template:Motorräder must definitely be moved to Template:Motorcycles. BTW the German translation is also misleading for the terms themselves. Yes, for this one use it is not needed, but potentially this templatebe longs into all categories regarding motorcyle/motorcycles. (Or am I wrong here?) The issue is you cannot request a simple bot run because there are surely some proper names, e.g. I think of subcategories of Category:Motorcycle Grands Prix. The same is true for Template:Train (it has no German translation). — Speravir – 23:22, 3 June 2020 (UTC)
Replying to Non-English speaking users in English
We need to be careful when a user whose native language is clearly not English posts here, then we reply in English.
For example, from File:OgataHaruna Instagram 2020-05-20.png:
- This file is uploaded according to Ogata Haruna's request(Person of photography).
- She requested to update wikipedia portrait picture and hope to use Instagram(2020-05-20) picture.
- (Ref. https://www.instagram.com/harunaogatajp/)
- (Ref. https://www.youtube.com/watch?v=tC7CD47I8sg&t=72s)
- For this reason, this picture never violate.
- I have uploaded again, so please don't delete it. — Preceding unsigned comment added by Sango captain (talk • contribs) 02:17, 2 June 2020 (UTC)
Clearly this user has a very poor understanding of English. Yet we gave them this boilerplate reply:
- Please do not reupload an image deleted in accordance with policy. Please also note that the copyright holder is the person who took the picture rather than the person who appears in it, unless the copyright was transferred by operation of law or by contract. For restoration, please have the actual photographer send permission and a specific release under an acceptable free licence using OTRS. Thank you for your understanding.
This has long, complex sentences (especially the second sentence) and some big words. At least the pages linked to have translation boxes at the top. But if the user is put off by the message quoted here, they might never follow the links.
I don’t know much about localisation; perhaps someone who does would like to comment on this? Brianjd (talk) 07:51, 2 June 2020 (UTC)
- Sango captain is Japanese. Maybe Miya can help. pandakekok9 08:00, 2 June 2020 (UTC)
- It would also be useful to have a list of which Village pumps in other languages are active so we could refer people appropriately. Commons:井戸端 isn't terribly active, but it does seem that the few times people ask questions there, they get a response. - Jmabel ! talk 14:48, 2 June 2020 (UTC)
- There's a discussion about something like that at COM:VPP#Create a Commons equivalent of Project:Embassy (Q1197883). clpo13(talk) 16:50, 2 June 2020 (UTC)
- It would also be useful to have a list of which Village pumps in other languages are active so we could refer people appropriately. Commons:井戸端 isn't terribly active, but it does seem that the few times people ask questions there, they get a response. - Jmabel ! talk 14:48, 2 June 2020 (UTC)
- I don’t see here a situation that needs any major (or minor) policy fix. Admins are already required to be helpful and polite with all users and the above is certainly not the former and argueably not the latter. I understand that admins are overworked but slapping a couple of hardly useful templates on a queary is not solving it — better leave it unanswered so that it can be deal with later or by another admin. (And let me plug here my pet peeve against pushing OTRS as the one and only solution for licensing and authorship confirmation needs, instead of a last resource.) -- Tuválkin ✉ ✇ 17:32, 4 June 2020 (UTC)
- @Tuvalkin: That's also my view, that OTRS is primarily useful for three things: 1) confirming the authenticity of an email address for a published file; 2) receiving a COM:AGF permission for an unpublished file for a creator with no Commons account; 3) having conversations that require divulging private details or sharing private files. Anything else is better done on-wiki. -- King of ♥ ♦ ♣ ♠ 18:05, 4 June 2020 (UTC)
fitting category-name?
We have already quite a number of recent images showing used facemasks and/or gloves thrown on the street during the current pandemic[1]. However, none of the images had specific category-name, which combined this kind of littering and the pandemic. So, for the english native-speakers: what would be a fitting and appropriate (universially understandable) category-name for that? "COVID-19 associated littering"? --Túrelio (talk) 15:02, 1 June 2020 (UTC)
- It’s hard to think of a good name – unless you want the name to be a whole sentence. However, I would caution against including the term “COVID-19” unless there is specific reason to believe that the images are COVID-19-related. Brianjd (talk) 15:12, 1 June 2020 (UTC)
- I was trying to find inspiration in existing categories, but all I found was another problem: Category:Cigarette butts is in Category:Littering, even though some cigarette butts are disposed of responsibly, which is not littering. Brianjd (talk) 15:15, 1 June 2020 (UTC)
- Thanks. Honestly, there is little doubt that it's COVID-19 associated. I've never in my life seen medical gloves and masks thrown on the ground of city streets before COVID-19. --Túrelio (talk) 15:19, 1 June 2020 (UTC)
- There is little doubt that the overall trend is COVID-19-related. But my worry is that all depictions of such littering will be placed in the category, even though some specific instances of PPE littering are not COVID-19-related. Brianjd (talk) 15:59, 1 June 2020 (UTC)
- Maybe “Littering of PPE during the COVID-19 pandemic”. Notice this doesn’t say the littering is related to the pandemic, only that it occurred during the pandemic, which is easy to verify. I’m not sure about the “Littering of” bit – this is where we should examine existing categories. Brianjd (talk) 15:18, 1 June 2020 (UTC)
- "PPE litter during the COVID-19 pandemic"? - Jmabel ! talk 15:58, 1 June 2020 (UTC)
- Is the term "PPE" easily understood? --Túrelio (talk) 16:09, 1 June 2020 (UTC)
- According to Category:Personal protective equipment, the term “PPE” is “common”. However, it’s also clear from this category and its many subcategories that the term should not be abbreviated in category names. So our current candidate is: “Personal protective equipment litter during the COVID-19 pandemic”. No, that’s too many adjectives and nouns strung together. Let’s try: “Littering of personal protective equipment during the COVID-19 pandemic”. What does everyone else think? Brianjd (talk) 16:18, 1 June 2020 (UTC)
- Not shorter, and makes me wonder how one does litter one's equipment. I prefer the verbless form. Hopefully somebody finds something shorter. There might also be a problem that "the" pandemic may not be well-defined (which we don't know yet). --LPfi (talk) 21:55, 3 June 2020 (UTC)
- According to Category:Personal protective equipment, the term “PPE” is “common”. However, it’s also clear from this category and its many subcategories that the term should not be abbreviated in category names. So our current candidate is: “Personal protective equipment litter during the COVID-19 pandemic”. No, that’s too many adjectives and nouns strung together. Let’s try: “Littering of personal protective equipment during the COVID-19 pandemic”. What does everyone else think? Brianjd (talk) 16:18, 1 June 2020 (UTC)
- It’s hard to think of a good name – unless you want the name to be a whole sentence. However, I would caution against including the term “COVID-19” unless there is specific reason to believe that the images are COVID-19-related. Brianjd (talk) 15:12, 1 June 2020 (UTC)
- There we are: Category:Littering of personal protective equipment during the COVID-19 pandemic. --Túrelio (talk) 09:48, 5 June 2020 (UTC)
After long discussion in the German motorsport portal (Link to discussion (German)) we've an aligned decison: The picture will not used further more in the German Wikipedia! We are thinking, it's modified too strong and suspect and without any references. Maybe a warning (or more?) for other wiki should be helpful?! Regards —Pitlane02 🏁 talk 19:25, 1 June 2020 (UTC)
- Pitlane02: if it is edited to the point of being misleading you can use {{Factual accuracy}} to draw attention to this. In this case, the description could do with rewriting to make this more clear additionally. ~~ Alex Noble/1-2/TRB 19:32, 1 June 2020 (UTC)
- {{Factual accuracy}} has now been added, but the remark is incoherent "Suspect, because it’s modified to strong, see also the discussion". I can't make head or tail of that. Could someone please expand on it a bit, either in English or in German? - Jmabel ! talk 02:02, 2 June 2020 (UTC)
- Perhaps {{Retouched picture}} as well? MKFI (talk) 06:10, 2 June 2020 (UTC)
- The remark should link to the discussion. Also the file is used on enwiki as well, so users there might be able to help (in English). Brianjd (talk) 06:59, 2 June 2020 (UTC)
- Since I got no response:
- "Suspect" all on its own: I'm guessing just means "This image is suspect" but isn't that what {{Factual accuracy}} means already? Or is this meant to say something else?
- What is "modified to strong" intended to mean? I'm not fluent in German, but my German is decent, and I'd have to translate that as "geändert nach stark" which makes no sense, surely something else was meant.
- Where it says "see also the discussion": what discussion? Link it (with a permalink)! - Jmabel ! talk
- I think your template suggestion was good, because we’re not sure, is it a fake or not, and in this situation we cannot recommending the usage.
- shameful, sometimes my English is not sufficient. “Modified too much“ sounds better, isn’t it?
- sorry, the discussion was archived yesterday, here the right link: https://de.wikipedia.org/wiki/Portal_Diskussion:Motorsport/Archiv/2020#File:Jordan_191_rain.png Thanks a lot for your support, regards — Pitlane02 🏁 talk 19:16, 2 June 2020 (UTC)
- @Pitlane02: Please have a look at my edit on the file page, let me know whether I understood correctly or not. - Jmabel ! talk 01:16, 3 June 2020 (UTC)
- @Jmabel: Great, you've put our concerns in a nutshell, from my point of view we're ready. Thanks a lot for your support and regards, --Pitlane02 🏁 talk 08:21, 5 June 2020 (UTC)
- {{Factual accuracy}} has now been added, but the remark is incoherent "Suspect, because it’s modified to strong, see also the discussion". I can't make head or tail of that. Could someone please expand on it a bit, either in English or in German? - Jmabel ! talk 02:02, 2 June 2020 (UTC)
Category:Jill Berelowitz
I wasn't aware that Jill Berelowitz is a male sculptor. But thank you for this information. 84.180.23.29 07:40, 2 June 2020 (UTC)
- Again, a good example of why these categories should not be diffused by gender. But apparently I'm in the minority on this. - Jmabel ! talk 14:40, 2 June 2020 (UTC)
- @Jmabel: Someone proposed somewhere that we ban category diffusion based on physical characteristics (except where those physical characteristics are actually relevant). I can’t remember where this proposal was but I would support it. Brianjd (talk) 15:29, 3 June 2020 (UTC)
- @Brianjd: It's currently open just over here: Commons:Village_pump/Proposals#Proposal:_avoid_excessive_use_of_gender_in_diffusing_categories. – BMacZero (🗩) 17:00, 3 June 2020 (UTC)
- @Jmabel: Someone proposed somewhere that we ban category diffusion based on physical characteristics (except where those physical characteristics are actually relevant). I can’t remember where this proposal was but I would support it. Brianjd (talk) 15:29, 3 June 2020 (UTC)
- I was a bit unsure, when the gender of Jill changed to female, but luckily it has now been restored to male. Thank you so much Wikipedia for not letting down the supreme gender. --84.162.0.254 18:45, 4 June 2020 (UTC)
- No, Berelowitz is not male, or at least does not consider herself to be so. From her own site: "Jill moved from her native South Africa to London… known for her bronze, steel and optical resin works… Jill’s detailed understanding of anatomy and organic form gifts her work with…" etc. (emphasis mine). - Jmabel ! talk 02:55, 5 June 2020 (UTC)
- @Tuvalkin: Can you explain this edit? https://commons.wikimedia.org/w/index.php?title=Category:Jill_Berelowitz&diff=423839090&oldid=423445795 - Jmabel ! talk 02:57, 5 June 2020 (UTC)
What’s the trouble? I didn’t know Jill can be a male name too, but okay.-- Tuválkin ✉ ✇ 03:18, 5 June 2020 (UTC)- Ah, now I read up. The IP in their OP was making use of sarcasm, bless their heart. -- Tuválkin ✉ ✇ 03:20, 5 June 2020 (UTC)
I need help adding a license for Portuguese Government's and Public Services' publications
Hi!
Under Portuguese Law (Council of Ministers No 95/99), any publication produced by the Portuguese Government or Portuguese Public Services can be "freely accessed and used by the public, as long as the source is mentioned", unless "specifically stated otherwise" in said publication.
I'd like to create a license tag (like the ones stated in Commons:Copyright rules by territory/Portugal#Copyright tags) concerning this kind of publications, so they can be more easily and accurately licensed upon upload.
I know my way fairly well around WP (I'm a rollbacker in the Portuguese version), but I must admit that I don't have enough knowledge about Commons' policies to create such a thing. Can anyone help me? Thank You! JonJon86 (talk) 14:02, 4 June 2020 (UTC)
- @JonJon86: Have a look at pretty much anything in Category:PD-USGov license tags for a model. - Jmabel ! talk 14:40, 4 June 2020 (UTC)
- @Jmabel: Thank you! Do you think I could just create the tag and publish it? Shouldn't it be proposed somewhere first, so more experienced users could vote to keep or delete it? JonJon86 (talk) 14:51, 4 June 2020 (UTC)
- @JonJon86 and Jmabel: I have created a draft version in English at User:De728631/workshop. I think this should get at least some consensus before being promoted to a live template. De728631 (talk) 21:54, 4 June 2020 (UTC)
- P.S.: We might also want to update Commons:Copyright rules by territory/Portugal. De728631 (talk) 21:56, 4 June 2020 (UTC)
- @De728631: Thank you! I think you should also add the "unless specifically stated otherwise in said publication" part, because it's very important. If a government publication uses any copyrighted work, it's always mentioned somewhere within that publication, and although it can be freely accessed by the public, its distribution or comercial uses may not be allowed. JonJon86 (talk) 22:44, 4 June 2020 (UTC)
- Thank you for pointing this out. I forgot about this part, but it is in fact important. It has now been added to the draft template. De728631 (talk) 22:49, 4 June 2020 (UTC)
- @De728631: have a look at https://freedomdefined.org/Definition . Currently it fails on the copies and the derivative works. Multichill (talk) 21:33, 5 June 2020 (UTC)
- @Multichill: Thank you for the message. I think though we have other templates where "use" is interpreted in a broader sense including copying and making of derivatives, as in "use for all purposes". De728631 (talk) 21:42, 5 June 2020 (UTC)
- Even if we have questionable templates that don't comply with Commons:Licensing, that doesn't make your template valid. Multichill (talk) 22:24, 5 June 2020 (UTC)
- @Multichill: Thank you for the message. I think though we have other templates where "use" is interpreted in a broader sense including copying and making of derivatives, as in "use for all purposes". De728631 (talk) 21:42, 5 June 2020 (UTC)
- @De728631: have a look at https://freedomdefined.org/Definition . Currently it fails on the copies and the derivative works. Multichill (talk) 21:33, 5 June 2020 (UTC)
- Thank you for pointing this out. I forgot about this part, but it is in fact important. It has now been added to the draft template. De728631 (talk) 22:49, 4 June 2020 (UTC)
- @De728631: Thank you! I think you should also add the "unless specifically stated otherwise in said publication" part, because it's very important. If a government publication uses any copyrighted work, it's always mentioned somewhere within that publication, and although it can be freely accessed by the public, its distribution or comercial uses may not be allowed. JonJon86 (talk) 22:44, 4 June 2020 (UTC)
- @Jmabel: Thank you! Do you think I could just create the tag and publish it? Shouldn't it be proposed somewhere first, so more experienced users could vote to keep or delete it? JonJon86 (talk) 14:51, 4 June 2020 (UTC)
Rollback confirmation – how to turn it off?
Recently a new feature has been introduced – rollback requires confirmation. When one clicks on "rollback" link, an additional message with "rollback" and "cancel" links appears. So one additional click is required in order to revert a change. How to turn off this feature? --jdx Re: 07:55, 5 June 2020 (UTC)
- Jdx: This appears to be Phabricator:T254538. ~~ Alex Noble/1-2/TRB 11:35, 5 June 2020 (UTC)
Photo challenge April results
| Rank | 1 | 2 | 3 |
|---|---|---|---|
| image | |||
| Title | Ein gutes Brot im eigenen Herd backen. | Baking chocolate chip banana bread | Preparation of mayonnaise |
| Author | Arquus | CrlNvl | Traumrune |
| Score | 16 | 10 | 3 |
| Rank | 1 | 2 | 3 |
|---|---|---|---|
| image | .jpg) |
 |

|
| Title | Pendulum clock in Bourvallais Hotel, Paris, France | Pendule d'officier | Wooden wall clock with pendulum and massive brass weights, half-hour chime |
| Author | Ibex73 | Cquoi | Franz van Duns |
| Score | 17 | 9 | 9 |
Congratulations to Ibex73, Cquoi, Franz van Duns, Arquus, CrlNvl and Traumrune. Also please come to Commons:Photo_challenge#Challenges_open_for_voting and vote for last month challenge photographs. -- Jarekt (talk) 00:53, 6 June 2020 (UTC)
An anonymous user created this category and some others. Not sure it actually exists because id:Kapuas Raya doesn't exist and the only thing I find on Wikidata is Kapuas Raya (Q26213741). I did find en:West_Kalimantan#Proposed_new_province_of_Kapuas_Raya, but can't verify the source. Anyone feels like diving into this one? Multichill (talk) 20:44, 3 June 2020 (UTC)
- en:West_Kalimantan#Proposed_new_province_of_Kapuas_Raya says it's proposed. i am unsure of the authenticity of the wd item.
- my suggestion: merge everything upward to west kalimantan (a real province).--Roy17 (talk) 10:37, 6 June 2020 (UTC)
Wikimirror replacing URLs
Wikimirror is apparently a way to get around various draconian internet restrictions and edit Wikimedia sites in Turkey, China, etc. However, it appears to have a bug whereby it occasionally replaces "wikimedia" with "wikimirror" in all URLs while performing an edit, which makes sense in some contexts, but definitely not in others (see e.g. User_talk:Leiem#Special:Diff/302584243/419115997 and Special:Diff/422802225/422863079). Zhwiki apparently has an edit filter exactly for this purpose (possibly zh:Special:滥用过滤器/298?). Should we use an analogous one? Storkk (talk) 07:29, 5 June 2020 (UTC) Ping @Rowingbohe, Leiem, and Jameslwoodward: affected parties. Storkk (talk) 07:33, 5 June 2020 (UTC)
 Support. It is useful for Wikimirror users. --Leiem (talk) 03:22, 6 June 2020 (UTC)
Support. It is useful for Wikimirror users. --Leiem (talk) 03:22, 6 June 2020 (UTC)- Support. It is useful for Chinese mainland users. --AnYiLinTalk 10:18, 6 June 2020 (UTC)
- I think this should actually be a global filter. Platonides (talk) 02:33, 7 June 2020 (UTC)
 Strong support: There are many users edit via these websites. We should set up a global EF to against the auto-replace. RuiyuShen (talk) 14:42, 7 June 2020 (UTC)
Strong support: There are many users edit via these websites. We should set up a global EF to against the auto-replace. RuiyuShen (talk) 14:42, 7 June 2020 (UTC)- Support and it's a good idea to set it as a global ep. (BTW, Cristian's wikimirror is not the same as wikimirror.org .)--Rowingbohe♬(Talk/Work) 14:57, 7 June 2020 (UTC)
Wann funktioniert der Uploadwizard eigentlich wieder?
Randbemerkung: Von meinem Home Office aus habe ich durch das Window nach draußen einen unverstellten Blick auf den VDSL-Verteilerkasten über den ich mien Internet beziehe. --C.Suthorn (talk) 13:12, 7 June 2020 (UTC)


- Nimm den commonisten, der funktioniert immer! Gruss --Nightflyer (talk) 13:54, 7 June 2020 (UTC)
Over diffusion of categories
I've whinged in the past here, about files being lost through being buried from sight by people who don't want images used, but spend their time in filing as a means to its own end. Imagine my dismay when I happened on this Category:December 1941 in Sydney. We have millions of files barely described without this nonsense. Broichmore (talk) 12:33, 1 June 2020 (UTC)
- I don’t understand what the problem is. Including so-called “nonsense” categories doesn’t prevent you from including other, more useful categories as well. How are files being “buried”? Brianjd (talk) 13:22, 1 June 2020 (UTC)
- The problem is taking a file and putting (filing) it out of sight. If the file is effectively lost, then how is it available for including other, more useful categories? I could think of ten more useful categories for that file than December 1941 in Sydney. We are supposed to make images available, that means keep them in open sight, not bury them in shoeboxes in the attic. Broichmore (talk) 13:34, 1 June 2020 (UTC)
- Then add those categories!!! What’s stopping you? If you mean that files where this is the only category should still be tagged with {{Check categories}}, then I agree, but that’s a separate issue. Also, the file in Category:December 1941 in Sydney already has other categories. So, again, what is the problem? Brianjd (talk) 13:56, 1 June 2020 (UTC)
- Say there’s a file in Category:December 1941 in Sydney. It’s not in any other categories and it’s not tagged with {{Check categories}} or anything like that. Now the file is hard to find, and it’s hard for people to add categories to it.
- Now say we delete Category:December 1941 in Sydney. The file is still hard to find. It’s still hard to add categories to it. What exactly do you propose? Brianjd (talk) 13:59, 1 June 2020 (UTC)
- The problem is taking a file and putting (filing) it out of sight. If the file is effectively lost, then how is it available for including other, more useful categories? I could think of ten more useful categories for that file than December 1941 in Sydney. We are supposed to make images available, that means keep them in open sight, not bury them in shoeboxes in the attic. Broichmore (talk) 13:34, 1 June 2020 (UTC)
- Brianjd is right and this needs to be repeated over and over. This is not a problem of “overdiffusion”, it is a problem of undercategorization. Furthermore Broichmore is escalating in their agressive, offensive language and over-the-top caricaturizing of other users — now we went from insults about misundertanding of categorization (right back at you) to accusations of sabotage («people who don't want images used»). -- Tuválkin ✉ ✇ 15:23, 1 June 2020 (UTC)
- That said: there is a real problem of people removing {{Check categories}} and other similar tags and categories after adding one not-very-informative category to an image. - Jmabel ! talk 15:57, 1 June 2020 (UTC)
- Tuvalkin I was wrong of course to employ sarcasm and should have said unwittingly don't want images used, but then of course you knew what I meant. Where are these insults directed at Brianjd or the escalation? You just twisted that. To call it insulting is OTT. Nevertheless, undercategorization? I of course agree its' undercategorization, of course it is. But that's not my point. Creating new categories should be done with caution, I see very little value in Sydney's case of catting below Sydney in the 1940s, the quantity of images doesn't justify it. Far better, all the images sit in decades (if not centuries) in this case. I would suggest that filing by year alone is, in effect, destructive. The files should all be in History of Sydney and maybe copied to the year if that's what you want. Even then if someone wants to find files by year then an SQL query is the better way to go. Maintaining multiple obscure cats once made is a problem, and once made they are seldom maintained. So your suggesting it's okay to file single images in obscure categories, nested in empty ones, as we can see ever increasing examples of in the project, provided that you fully categorize every piece of minutiae in an image? How is that to be policed, when a simpler way is to say if filing by time then there should be a limit of at least 20 images eligible for posting to such a cat. Broichmore 16:44, 1 June 2020 (UTC)
- @Broichmore, Tuvalkin, and Jmabel: The previous comment was added in this diff: Special:Diff/423183072. It was signed with a time but not a name; I have added the name. Interesting. Brianjd (talk) 06:42, 2 June 2020 (UTC)
- I don’t understand how bigger categories would be easier to maintain. They might, in fact, be harder to maintain.
- How many people do you know that know SQL (or anything else to do with databases), excluding people who work in a relevant field? (This is the one area where I would say you might have a point, now that we have things like FastCCI. But this alone is not a reason to make major changes to our categorisation system.)
- Categories that contain other categories are not empty.
- Finally, there’s this really cool thing called paragraphs. They make it so much easier for other people to read your messages. Brianjd (talk) 06:54, 2 June 2020 (UTC)
- Tuvalkin I was wrong of course to employ sarcasm and should have said unwittingly don't want images used, but then of course you knew what I meant. Where are these insults directed at Brianjd or the escalation? You just twisted that. To call it insulting is OTT. Nevertheless, undercategorization? I of course agree its' undercategorization, of course it is. But that's not my point. Creating new categories should be done with caution, I see very little value in Sydney's case of catting below Sydney in the 1940s, the quantity of images doesn't justify it. Far better, all the images sit in decades (if not centuries) in this case. I would suggest that filing by year alone is, in effect, destructive. The files should all be in History of Sydney and maybe copied to the year if that's what you want. Even then if someone wants to find files by year then an SQL query is the better way to go. Maintaining multiple obscure cats once made is a problem, and once made they are seldom maintained. So your suggesting it's okay to file single images in obscure categories, nested in empty ones, as we can see ever increasing examples of in the project, provided that you fully categorize every piece of minutiae in an image? How is that to be policed, when a simpler way is to say if filing by time then there should be a limit of at least 20 images eligible for posting to such a cat. Broichmore 16:44, 1 June 2020 (UTC)
- @Jmabel: I’m not familiar with this issue, but if these users are adding exactly one category before removing such tags, it could be because they don’t understand that files can (and usually should) be in multiple categories. Brianjd (talk) 06:56, 2 June 2020 (UTC)
- @Brianjd: I work a lot on categorizing bot-added photos from GLAMs, and I would say that in my experience it happens to more than 10% of those. - Jmabel ! talk 14:29, 2 June 2020 (UTC)
- That said: there is a real problem of people removing {{Check categories}} and other similar tags and categories after adding one not-very-informative category to an image. - Jmabel ! talk 15:57, 1 June 2020 (UTC)
- @Brianjd: My excuse for large numbers of images in a category is that our best search tool is the human eye, but it only works if images are within its range.
- The problem filing by year is, what might have been one click into a decade is now ten plus by year, and potentially 130 if by month. Thats what I mean by hiding them.
- It's actually a simple matter to scan hundreds of images, I do it every day. Broichmore (talk) 15:00, 3 June 2020 (UTC)
- Finally, a decent explanation. This is actually a good point, but we should probably fix this through better software. Brianjd (talk) 15:16, 3 June 2020 (UTC)
- I'd love to have this fixed by better software, but until it is here and in common use, we have to keep the category system working. And this is a real problem. If the by year categories are used in addition to other categories, there is no problem, but when a category is split by year, keeping a file in the split category is seen as overcategorisation. So now you cannot find it were it is easy to find. Splitting by year might sometimes be sensible when the main category is large, but often other criteria are more meaningful, and finding by year is much more work than just clicking for the next 200 files if you aren't interested in a certain year, especially if the by year categories are small. --LPfi (talk) 21:47, 3 June 2020 (UTC)
- In my opinion, subcategorization by date can be used either to fully diffuse a main category or solely as a supplement. If the subject is a single thing (e.g. Category:Eiffel Tower) where most of the photos will look very similar to each other and there just isn't a really good way to subcategorize otherwise, then emptying the main cat into the dated cats makes sense. However, if the subject is very broad (e.g. Category:New York City), then forcing a full diffusion into date categories doesn't make sense. Instead, photos should either be double-categorized into the main category or (even better) fully diffused into non-date subcats. -- King of ♥ ♦ ♣ ♠ 22:00, 3 June 2020 (UTC)
- I'd love to have this fixed by better software, but until it is here and in common use, we have to keep the category system working. And this is a real problem. If the by year categories are used in addition to other categories, there is no problem, but when a category is split by year, keeping a file in the split category is seen as overcategorisation. So now you cannot find it were it is easy to find. Splitting by year might sometimes be sensible when the main category is large, but often other criteria are more meaningful, and finding by year is much more work than just clicking for the next 200 files if you aren't interested in a certain year, especially if the by year categories are small. --LPfi (talk) 21:47, 3 June 2020 (UTC)
- Catting by date can only be supplemental at best.
- I agree with everything King of Hearts said, if we’re going to use dates by then images need to be double-categorized into the main category or (even better) fully diffused into non-date subcats.
- Finally, a decent explanation. This is actually a good point, but we should probably fix this through better software. Brianjd (talk) 15:16, 3 June 2020 (UTC)
- I was accused of over-excitement earlier, and perhaps there should be some explanation for that. I almost exclusively hunt down images of ships and steamboats here. The main purpose is to upload their images if notable into Wikipedia, or make them available as a supplement to Wikipedia. A side product of that is specific categorisation of the image into (examples) HMS Foo, (Sidewheel riverboat Foo), Atlantic convoy, etc for future potential use in Wikipedia.
- Ship images are very often uncatalogued as such, and are instead lying hidden inside images in major cats such as Mississippi River, Views of Foo, Marine art by Foo, Paintings by foo, Engravings of Foo. These images often have to be visually identified, there being no mention in the text of the boat. The scene may be of a river, whatever. The boat’s name if your lucky is printed on the side of the vessel, or it has to be identified by other means. This does not apply just to ships, it could be almost any object you could imagine, bridges, dresses, faces, beggars, bouquets, people playing chess, traffic lights, etc.
- Too find these images requires scanning through tranches of images. Commonly in main cats holding between 1 to say 3,500 images. Entire museum collections. That’s not as hard as it sounds, when using multiple screens, at least one set to vertical orientation and scrolling through 500 images at a time, it can be tedious, but fruitful. Example File:Cincinnati, Ohio.jpg contains Steam packet ‘’Bonanza’’.
- After a while of doing this you get to sense other images on the way that are likely lost. The majority of images I’m searching for or dealing with are historical images, not modern day photography. The explosion of digital photography, the sheer quantity of images, has made the overwhelming majority trivial to say the least. Not to mention the time soaking problems that copyright laws present.
- On a slightly separate note, IMO the category system is at threat, by Wikidata. Infoboxes are taking over the role that was performed by categories. Where there are duplications between wikidata and commons the duplicate commons categories are being systematically deleted; because they are already represented in the infobox. As the Infoboxes expand by adding data to them the categories get deleted. Cats as we know them, could entirely disappear.
- This is a problem; Wikidata is totally reliant on the input of data, and that’s only achieved by manually categorising files, it doesn’t happen the other way round.
- Wikidata structured data fields are for machines (ie Google Image search) etc. However it falls short of the efficiency of the Google engine, and doesn't perform as well as its touted. Perhaps it’s too early as it’s still in development. It’s my belief that Wikidata and old fashioned categorising should be regarded as totally separate things and one cannot supplant the other. Commons categorising being the superior of the two.
- It’s my contention that attempting to properly and fully categorise an image (on a minimal basis) is hard enough already without the added hurdles of taking into account information already there in infoboxes or in hidden categories. I don’t see how such a complicated environment can allow cataloguing to be done without duplication or for it to be a rewarding experience.
- Deleting {{Check categories}} too early is a problem, perhaops covered by an "are you sure, warning"? As is mis-catting, many historical 16th , 17th, 18th century images of place are being taken out of say “History of Foo in the 18th century” and being put in ‘’Foo in the 18th century in art’’ for instance. Given that all historic images of place from the 17th century are art by default, moving them is a grave error. Broichmore (talk) 15:30, 4 June 2020 (UTC)
- Why is moving them a grave error? Not all files in History of Foo in the 18th century are going to be artwork, e.g. books, blueprints, diagrams. Artworks should be in art categories, even if there's an argument for putting them History of Foo as well.--Prosfilaes (talk) 04:38, 6 June 2020 (UTC)
- Either have them in both or add a {{Cat see also}}, or make the "in art" category a subcat of the "history of". It just has to be done consistently. Double categorization will never be done consistently, so either of the other ones needs to be done. --LPfi (talk) 08:33, 8 June 2020 (UTC)
- Why is moving them a grave error? Not all files in History of Foo in the 18th century are going to be artwork, e.g. books, blueprints, diagrams. Artworks should be in art categories, even if there's an argument for putting them History of Foo as well.--Prosfilaes (talk) 04:38, 6 June 2020 (UTC)
- Deleting {{Check categories}} too early is a problem, perhaops covered by an "are you sure, warning"? As is mis-catting, many historical 16th , 17th, 18th century images of place are being taken out of say “History of Foo in the 18th century” and being put in ‘’Foo in the 18th century in art’’ for instance. Given that all historic images of place from the 17th century are art by default, moving them is a grave error. Broichmore (talk) 15:30, 4 June 2020 (UTC)
Request for comment: Do our files of individual road signs have a unique history?
I would have considered that our representations of road sign images would have a valid history, and where they are updated by the regulatory authorities that they should have a new version uploaded to a new name as a new edition, rather than be overwritten. To me the guidance at Commons:Overwriting existing files would generally indicate that each version of a sign does have its history as one might wish to portray a sign's evolution through history, though it is not totally specific in this space. In my administration role, I am needing to know the community's opinion on whether road signs are essentially generic by jurisdiction and we do NOT maintain edition control and as such be overwritten, or we consider the unique entities that should not be overwritten as a sign changes in time (ie. edition control, and could be managed and retained).
Examples:
- File:A13-LV.svg a colour change
- File:Armenian road sign 3.13.svg change in letters/font/... used
Noting that I am not talking updates for a better rendition of the sign, I am talking about the regulatory changes, eg. wording, a stated colour change, etc.
Where I have reverted I have instructed the editors to upload their alternate versions separately to a name pattern they can use, and then separately deal with any issues surrounding old files. Thanks for your comments and feedback, it will enable to better reflect the community's wishes in my actions. — billinghurst sDrewth 04:23, 6 June 2020 (UTC)
- It may be worthwhile keeping an example when style changes as a means of illustrating the overall style. However we do not need old versions of every single sign - a single example will do. Any old versions kept should be renamed, as we do with flags. Other than that, I don't see an issue with overwriting here; I don't see a compelling educational use for having an old version of A13 and of A14 and of A15 etc. Pi.1415926535 (talk) 05:09, 6 June 2020 (UTC)
- If you want to create scenery from a certain time (in an educational game, say) you would like to have access to the contemporary version of the sign. I see no reason to upload the new one under the same name. What about an article discussing the 2020 reform? If it uses the filenames of the current versions and those are "updated" in the next reform, there will be a mess. Instead, make the names pointing to the current versions redirects, and change the redirects when new versions become current. --LPfi (talk) 19:30, 6 June 2020 (UTC)
- LPfi is right. -- Tuválkin ✉ ✇ 18:24, 7 June 2020 (UTC)
- That's an enormous amount of effort - maintaining an large number of redirects - for a very small number of mostly theoretical use cases. It would be much more practical to just update the main file, and split out on old version if and when a specific use case arises. Pi.1415926535 (talk) 22:29, 7 June 2020 (UTC)
- To me the road signs should not have the generic names, they should be always be fully explicit and qualified, rather than just a generic name. What does "A13-LV" even mean? How many roads igns around the world have "A13"?
We have Wikidata that can manage the history of road signs, and sign changes and be able to give times and dates and users can have their templates that calls the current version. — billinghurst sDrewth 00:23, 8 June 2020 (UTC)
- If we were to give up about curating all kind of nexual interconnections between our media files and to rely on Wikidata for that job — that is, having all Commons cats with zero parent cats and zero child cats, in the limit case (and I’m not saying we should do that, quite the opposite), even then, reduced to the task of solely curating each individual file or atomic set of files, in separate, we would still need to have separate images for each different rendering of those road signs, in their more or less subtle diachronic variations. To be clear, even though I radically disagree with billinghurst concerning Wikidata, I also think we should keep separate files/filenames for all these. On the other hand, I understand the concerns raised by those favouring a synchronic approach, but this issue was already risen in Commons and solved long ago: Just do the same as it is done with national flags — which are way more widely reused in Wikipedia and elsewhere than road signs will ever be, and whose diachronic variation is usually all but subtle. -- Tuválkin ✉ ✇ 01:18, 8 June 2020 (UTC)
- If you think updating redirects is too big an effort, then don't create the redirects, just upload under new names. Is there any reason to suppose the majority of uses are such that updates are wanted? Even articles about current signs might have captions referencing the at-time-of-writing current versions. What is the biggest job: to update file names in an article about the current traffic signs (which probably has to be amended anyway when legislation changes), to update redirects, or to first wonder why captions and images don't match, then find the old version and make it a new file, and finally change the references? To avoid the false captions lingering, you need to separate the time-bound versions at the moment you start using them, which is much more work than updating a redirect (and is hard to do for non-wikimedia users). --LPfi (talk) 08:14, 8 June 2020 (UTC)
- If we were to give up about curating all kind of nexual interconnections between our media files and to rely on Wikidata for that job — that is, having all Commons cats with zero parent cats and zero child cats, in the limit case (and I’m not saying we should do that, quite the opposite), even then, reduced to the task of solely curating each individual file or atomic set of files, in separate, we would still need to have separate images for each different rendering of those road signs, in their more or less subtle diachronic variations. To be clear, even though I radically disagree with billinghurst concerning Wikidata, I also think we should keep separate files/filenames for all these. On the other hand, I understand the concerns raised by those favouring a synchronic approach, but this issue was already risen in Commons and solved long ago: Just do the same as it is done with national flags — which are way more widely reused in Wikipedia and elsewhere than road signs will ever be, and whose diachronic variation is usually all but subtle. -- Tuválkin ✉ ✇ 01:18, 8 June 2020 (UTC)
- To me the road signs should not have the generic names, they should be always be fully explicit and qualified, rather than just a generic name. What does "A13-LV" even mean? How many roads igns around the world have "A13"?
- That's an enormous amount of effort - maintaining an large number of redirects - for a very small number of mostly theoretical use cases. It would be much more practical to just update the main file, and split out on old version if and when a specific use case arises. Pi.1415926535 (talk) 22:29, 7 June 2020 (UTC)
- If you want to create scenery from a certain time (in an educational game, say) you would like to have access to the contemporary version of the sign. I see no reason to upload the new one under the same name. What about an article discussing the 2020 reform? If it uses the filenames of the current versions and those are "updated" in the next reform, there will be a mess. Instead, make the names pointing to the current versions redirects, and change the redirects when new versions become current. --LPfi (talk) 19:30, 6 June 2020 (UTC)
en:wiki mentioned twice
I may very well have missed something, but why is the English Wikipedia the only one mentioned twice in the left column of this page, both in the in Wikipedia section and in the in other projects section? Why does that happen on many, many other Commons pages, for that matter? Regards, Wutsje 02:32, 8 June 2020 (UTC)
- @Wutsje: Have you by any chance selected English as your default language? - Jmabel ! talk 05:01, 8 June 2020 (UTC)
- @JMabel: Yes, I have. But changing that in cy, de, fy, nl, sv and vi doesn't change anything, the Wikipedia link in the in other projects section on this page keeps linking to the en:wiki Village pump. On any other Commons page I tried, that link links to the corresponding en:wiki page. Wutsje 05:41, 8 June 2020 (UTC)
- @Wutsje: OK, that sounds like it shouldn't be that way. I'm sure you can see why I asked. - Jmabel ! talk 05:49, 8 June 2020 (UTC)
- Sure, I do, no problem. It looks like some kind of bug to me. Wutsje 05:51, 8 June 2020 (UTC)
- @Wutsje: OK, that sounds like it shouldn't be that way. I'm sure you can see why I asked. - Jmabel ! talk 05:49, 8 June 2020 (UTC)
- @JMabel: Yes, I have. But changing that in cy, de, fy, nl, sv and vi doesn't change anything, the Wikipedia link in the in other projects section on this page keeps linking to the en:wiki Village pump. On any other Commons page I tried, that link links to the corresponding en:wiki page. Wutsje 05:41, 8 June 2020 (UTC)
- @Wutsje: This is phab:T111913. The "Other projects" box only supports one link per project, and the sites to be linked to have to be specified in static configuration. That means they can't be changed dynamically with your interface language unless someone develops a crazy JavaScript hack to replace the functionality. --AntiCompositeNumber (talk) 06:34, 8 June 2020 (UTC)
- Ah, thanks for your explanation. We'ĺl have to wait for that then. Regards, Wutsje 13:57, 8 June 2020 (UTC)
Emails detailing bot changes
Hi. I'm assuming this is the right place to raise this. I find it irksome to receive hundreds of email notifications for bot changes, such as from SchlurcherBot, EatchaBot, JarektBot, which clog up my inbox and require mass deletions without opening them. Such bot edit notifications I would like to block; they are rarely contentious, but could cause me to miss edits that might be. In 'notifications' I can't see anyway of doing this. Can anyone advise on bot email block. Thanks. Acabashi (talk) 09:10, 9 June 2020 (UTC)
- On your Preferences page, section Notifications, you should be able to deselect any notification by e-mail (and by web). I think this is the link: https://commons.wikimedia.org/wiki/Special:Preferences#mw-prefsection-echo, but you should be able to reach it easily by the Preference button. Hope this helps, Acabashi. Eissink (talk) 12:31, 9 June 2020 (UTC).
- Thanks for that Eissink. I've added those bots under the 'Muted users', so we'll see if it works. Appreciated. Acabashi (talk) 12:44, 9 June 2020 (UTC)
Combining Wikidata pages
I have created Category:Jürgen Rühle. As I did not find a link to Wikidata on page de:Jürgen Rühle, I created a Wikidata page. When I wanted to add the German Wikipedia page I got an error. There is already a Wikidata page. How to combine these pages? Wouter (talk) 08:45, 7 June 2020 (UTC)
- It was done in the meantime. See d:Help:Merge for next time (it's not that rare at Wikidata). Jura1 (talk) 10:17, 7 June 2020 (UTC)
- (Edit conflict) Wouterhagens, I've merged it for you. There is a gadget to do so, under preferences on Wikidata. This gives a GUI to merge items together. ~~ Alex Noble/1-2/TRB 10:19, 7 June 2020 (UTC)
- Thank you very much. Now it is also possible from the German WP to get the Wikidata page from "Links hinzufügen". Wouter (talk) 11:53, 7 June 2020 (UTC)
- I have created many of those links, but I think I never created a standalone WD entry manually: At the lower left of any category page (using Monobook here with most cruff turned off — YMMV) there is a section that says
Click it, select the related Wikipedia article (in any language) and the linkage is then established, including to an WD entry (either already existing or created anew). This is one of the few things about WD that seems to be an added value to our work and that works well almost always. -- Tuválkin ✉ ✇ 01:04, 8 June 2020 (UTC)In Wikipedia
Add links
- I tried the procedure you mentioned after creating a new category. I did not see the button "Add links", even when I switched from Vector to Monobook. The problem I had was that there was no link to Wikidata in the German WP article from "Links hinzufügen", but later (after the merge) there was that link. Wouter (talk) 12:33, 9 June 2020 (UTC)
Where is the page where you can see all of the usages of your uploaded files?
Hi everyone, I remember recently seeing a page that listed all of your files that were used on different wikis and links to those pages where your files are used. However, I sadly can't seem to find that page anymore. Could anyone tell me if they know where I can find such a page?
Thanks in advance,
Best regards, NeoMeesje (talk) 18:26, 8 June 2020 (UTC)
- @NeoMeesje: I think this might be what you're looking for: https://tools.wmflabs.org/glamtools/glamorous.php. – BMacZero (🗩) 22:07, 8 June 2020 (UTC)
- It is! Thank you so much! NeoMeesje (talk) 06:21, 9 June 2020 (UTC)
(Icon) Template driven categorization
Quality images (QI) can easily be identified by a green icon on the right upper side of the file page. That icon is added by the template {{QualityImage}}, and that template also places the file in the Category:Quality images. Now, in regular categorizing we don't want images to be in the main category when it's already in a subcategory, but when a QI has been placed in a subcategory, due to the QI-template it also remains in the main category (which holds hundreds of thousands of images now). For instance: File:Monumento a Tito Speri a Brescia.jpg, which is in two QI-subcategories and in the main category. Removing the QI-template does remove it from the main category, but it also removes the green QI-icon.
Would it not be preferable to fix this? Would it be possible to automitacally attach the QI-icon to every image in a subcategory, and simultaneously remove it from the main category? It seems like this is something that can be done by a bot. This question might apply to other template driven categorisations as well – do we want such templates to oppose regular, standard categorization?
Has this perhaps been discussed before? Is it something to fix or should this go on for the decades and decades to come? Eissink (talk) 12:26, 9 June 2020 (UTC).
- @Eissink: My understanding is: Categories can be divided into topic categories (which describe the contents of the file) and non-topic categories (which describe other things). Non-topic categories are marked with __HIDDENCAT__ and appear smaller (or hidden) in the list at the bottom of a page. Topic categories should obey COM:OVERCAT and hence are rarely applied by templates. Non-topic categories do not have to obey COM:OVERCAT and are often applied by templates. How any particular non-topic category tree should be handled is a separate matter. I am very happy with the fact that {{Geograph}} categorises every Geograph image into Category:Images from Geograph Britain and Ireland because that makes a lot of searches easier. That might or might not be the case for quality images. --bjh21 (talk) 13:26, 9 June 2020 (UTC)
- Thank you, bjh21, that is a clarifying set of remarks. A difference between the QI-template and f.i. the Geograph-template, is that the latter reflects an external fact, while the QI-dedication is a subjective, internal Commons-qualification. Maybe that is what triggered me: the choice to qualify an image as a QualityImage is more or less rational, equal or paralel to the lines of logic that apply in topic categorization, unlike the Geograph-categorization. But I don't want to raise too much questions on this, so I thank you for your clarification and leave it there, unless someone else jumps in. Eissink (talk) 14:19, 9 June 2020 (UTC).
Prototyping media search
As you may have seen, the Structured Data team has a new media search prototype up for feedback. To copy the page's nutshell, Special:MediaSearch is an alternative, image-focused way to find media on Commons. MediaSearch uses categories, structured data and wikitext from Commons, and Wikidata to find its results. The team has received a lot of helpful responses so far, and is looking to hear more about what you think. If you can find some time to look it all over, it would be appreciated. Thanks. Keegan (WMF) (talk) 19:04, 9 June 2020 (UTC)
Dissapeared Wikidata link
I noticed that the link to related Wikidata item dissapeared from the "tools" section of the left menu. Is it meant as some improvement, or it's just a bug? --ŠJů (talk) 20:15, 5 June 2020 (UTC)
- I can still see it. Ruslik (talk) 20:29, 5 June 2020 (UTC)
- I had the same problem for a bit today! --Richard Arthur Norton (1958- ) (talk) 21:01, 5 June 2020 (UTC)
@Ruslik0 and Richard Arthur Norton (1958- ): No answer, no explanation, but it seems to be fixed today. --ŠJů (talk) 22:26, 10 June 2020 (UTC)
Incorrect coordinates
Hello, is there a template for tagging images that have incorrect coordinates? Keith D (talk) 23:57, 8 June 2020 (UTC)
- @Keith D: I suspect not. I suppose you could use {{Fact disputed}}. - Jmabel ! talk 02:51, 9 June 2020 (UTC)
- @Jmabel: Thanks - I have picked {{Factual accuracy}} from the doc on the {{Fact disputed}} template. Keith D (talk) 11:02, 9 June 2020 (UTC)
- @Keith D and Jmabel: I think, such a special tagging template can be created, as well as we have {{Wrong date}} and {{Invalid Exif date}}. However, when you check Category:Geocoding templates, you can find {{Location estimated}}, {{Location rounded}} and {{Location withheld}}. If the coordinates at the file page are absolutely wrong, they should be rather deleted than tagged. Some template should be created to supress (avoid) import of incorrect metadata (EXIF) coordinates. --ŠJů (talk) 22:21, 10 June 2020 (UTC)
- @ŠJů: By just deleting the co-ordinates it will leave the image without any and no indication of where it is, unless there is a template to tag that the file needs co-ordinates adding to get it in some maintenance category. I would guess that the coordinates are out by about a mile, I could tweak them to get closer but that would be a guess as unsure which of a number of sets of steps that the photo is of. Keith D (talk) 22:43, 10 June 2020 (UTC)
- @Keith D and Jmabel: I think, such a special tagging template can be created, as well as we have {{Wrong date}} and {{Invalid Exif date}}. However, when you check Category:Geocoding templates, you can find {{Location estimated}}, {{Location rounded}} and {{Location withheld}}. If the coordinates at the file page are absolutely wrong, they should be rather deleted than tagged. Some template should be created to supress (avoid) import of incorrect metadata (EXIF) coordinates. --ŠJů (talk) 22:21, 10 June 2020 (UTC)
- @Keith D: As mentioned above, if the coordinates are absolutely nonsense, they give no indication of where it is and can be deleted. When they define only the city (a definition point of the city or quarter, but not the correct location - typical for some Flickr imports etc.), they can be tagged as "estimated" or "rounded" but rather replaced with a tag of some maintenance category (e.g. Unidentified location in Paris). It's usually a good idea to find a whole set of photos that have exactly the same coordinates (using in-source searching). --ŠJů (talk) 22:55, 10 June 2020 (UTC)
- @ŠJů: It is a file imported from panoramio and it is just 1 file of the set that is incorrect, the coordinates do give some general idea of where the file is. Keith D (talk) 23:04, 10 June 2020 (UTC)
- @Keith D: In such individual case, I would remove or hide the wrong coordinates, and add a category of the city/village/region (if probable), and add an explanation to the file description – a mention of previous and next uploaded files of the uploader etc.
- @ŠJů: It is a file imported from panoramio and it is just 1 file of the set that is incorrect, the coordinates do give some general idea of where the file is. Keith D (talk) 23:04, 10 June 2020 (UTC)
- @Keith D: As mentioned above, if the coordinates are absolutely nonsense, they give no indication of where it is and can be deleted. When they define only the city (a definition point of the city or quarter, but not the correct location - typical for some Flickr imports etc.), they can be tagged as "estimated" or "rounded" but rather replaced with a tag of some maintenance category (e.g. Unidentified location in Paris). It's usually a good idea to find a whole set of photos that have exactly the same coordinates (using in-source searching). --ŠJů (talk) 22:55, 10 June 2020 (UTC)
This 2-person dispute has simmered for 2 weeks and could use additional opinions. It concerns a corporate publicity photo of w:Elizabeth Holmes of Theranos corp. The top of the page shows a closed discussion, further down is the active deletion request. Thanks. -- GreenC (talk) 03:58, 10 June 2020 (UTC)
disambiguation pages as SDC tags
To File:2019 WNBR Brighton 181.jpg 11 SDC tags have been added with 11 edits. 3 (or maybe more) of these tags are disambiguation pages.
Ich habe (mehrfach?) vorgeschlagen, die Softwareteile zum Einfügen von SDC solange zu deaktivieren, bis die bekannten Fehler behoben sind. Begriffsklärungsseiten als Tags und das wird nicht von der Software verhindert? Im Ernst? Bei einer der weltweit Top 10 Websites?
Hier noch ein paar Pings an WMF Accounts hindenken und einen Link auf einen Phab-task.
Gibt es eigentlich einen Barnstar, wenn man Fehler in SDC entdeckt?
--C.Suthorn (talk) 16:38, 10 June 2020 (UTC)
- NSFW warning about that linked photo: nudity, including male genitalia. - Jmabel ! talk 01:03, 11 June 2020 (UTC)
- The tags are Wikidata items; if they are items for disambiguation pages (I assume that is the meaning of Begriffsklärungsseite), yes it is odd for a tool to offer them. It is unlikely that anyone here at the village pump can do anything about that, though, I'd suggest reporting it at Commons talk:Structured data/Computer-aided tagging.
- By the way, I'd say the tags on that image almost entirely miss the point of what the picture depicts; some of them are close to imbecile, and none of them is World Naked Bike Ride (Q986161), clearly the single most relevant item for what this image depicts. - Jmabel ! talk 01:12, 11 June 2020 (UTC)
- That is more a problem of people do not check what they add before they add any statements. There are many statements with random books or places thousand of km away. As you see in these example these are new registered users do not having any other contributions and never contribute again after this. --GPSLeo (talk) 08:31, 11 June 2020 (UTC)
- BTW: THe file has a personality rights template and the category a nuditiy template. Are there tags for that? Maybe autoincludable via the templates? --C.Suthorn (talk) 08:46, 11 June 2020 (UTC)
- @GPSLeo: I would say it is a problem with the tool that a single action by an inexperienced user is sufficient for us to put a tag on an image. Also that it apparently suggests a bunch of crappy tags and not the ones that are actually useful. - Jmabel ! talk 14:47, 11 June 2020 (UTC)
- Yes with that vandalism is easier and faster then with editing wikitext. But the crappy suggestions are not the problem here because at least disambiguation pages never are suggested to be added. --GPSLeo (talk) 14:52, 11 June 2020 (UTC)
- @GPSLeo: I would say it is a problem with the tool that a single action by an inexperienced user is sufficient for us to put a tag on an image. Also that it apparently suggests a bunch of crappy tags and not the ones that are actually useful. - Jmabel ! talk 14:47, 11 June 2020 (UTC)
- I understand that the suggestions originate from AI image analysis. The AI finds in an image a cat, a dog and an elephant, and then suggests the tags cat, dog and elephant. But it should instead suggest tags based on existing categories like:
- cats chasing dogs while elephants are watching
- cats, dogs and elephants picnicking at night
- oil paintings of cats and dogs with elephants
- all of which are subcats of the cats, dogs, and elephants categories. ping user:Keegan (WMF) --C.Suthorn (talk) 15:18, 11 June 2020 (UTC)
- Thanks for the report, C.Suthorn. Currently, the software is only sending the image with no accompanying context for machine vision analysis. This is largely for privacy reasons, as sending along content like category inclusion could potentially be providing personally identifying information. The solution for now is to show the categories once the image is back with suggestions, with the intention of people adding statements based on the category if the suggestions are too vague or ill-fitting for a particular image.
- There's certainly still room for improvement in how this is working for some editors, I'll pass along the details here and see if there are design changes that might help the issue. Keegan (WMF) (talk) 17:37, 11 June 2020 (UTC)
Flickr CC-0
I was under the impression that we cannot import public domain/CC-0 media from Flickr because we communally decided that it's too risky but it looks like File:5-27-2020 (39 of 61) (49943844691).jpg this was successfully reviewed by a bot. What am I missing? —Justin (koavf)❤T☮C☺M☯ 20:34, 5 June 2020 (UTC)
- CC-0 is perfectly fine as it is a licence granted by the original copyright holder. What we don't want is the Public Domain Mark {{Cc-pd}} which is just a generic statement that something is PD for some obscure reason. De728631 (talk) 20:41, 5 June 2020 (UTC)
- Gotcha. Thanks. —Justin (koavf)❤T☮C☺M☯ 21:05, 5 June 2020 (UTC)
- And there is no outright ban on {{Cc-pd}} material from Flickr; it's just that the quasi-license there is useless, so you need to add an actual justification for why something is PD, e.g. {{PD-ineligible}}, {{PD-old-100}}, etc. - Jmabel ! talk 21:51, 5 June 2020 (UTC)
- I think, files released on flickr as "Public Domain" are OK on Commons as long as the files were released to public domain by the photographers. "Public Domain" files linking to CC-O are preferable but files linking to Public Domain Mark meet the requirements of COM:LIC policy. We usually add {{PD-Author}} to such files. --Jarekt (talk) 01:03, 6 June 2020 (UTC)
- I think {{PD-author}} can only be properly used by the author themselves, since it's not possible to grant a license on their behalf, i.e., "{{{1}}} grants anyone the right to use this work for any purpose, without any conditions, unless such conditions are required by law." --ghouston (talk) 10:00, 6 June 2020 (UTC)
- --ghouston, I see your point the first sentence "This work has been released into the public domain by its author, {{{1}}}. This applies worldwide." is fine when applied to flickr images released to Public domain by the authors, but the second sentence is more of an issue. The first sentence, applies to US and countries where release to "public domain" is recognized by law and is sufficient to meet requirements of COM:LIC. Maybe in case of the "PD by author" images from flicker we should drop the second sentence as the legal situation in some countries (which countries?) is unclear, or replace it with "In some countries this may not be legally possible, if so than in those jurisdictions the copyright status is unclear". --Jarekt (talk) 17:15, 8 June 2020 (UTC)
- It would be better to have a custom template for the Flickr PD-Mark own-work files, if they are going to be accepted, which would explain the assumptions that have been made: that the Flickr uploader is the author, and that they've apparently released it to the public domain. --ghouston (talk) 01:51, 9 June 2020 (UTC)
- What is strange is that {{PD-self}} is identical to {{PD-author}} except it is for cases where author is the uploader, so {{PD-author}} should be for images where author is not the uploader. Also on other Wikipedia project the template with just the first sentence is called Template:PD-release (Q6208203). --Jarekt (talk) 02:31, 9 June 2020 (UTC)
- I'm not sure that there'd even be many cases where the uploader isn't the author, but the author did agree to that specific license. --ghouston (talk) 02:37, 9 June 2020 (UTC)
- I agree, that is strange. In some documentation {{PD-author}} is mentioned as for cases where author is from external website. I noticed we also have a lot of files with {{PD-release}} tag transferred from other projects. At the moment {{PD-release}} redirects to {{PD-self}}. So it seems like the second sentence is added automatically to many PD files even when it is unclear that author did agree to that specific license. My guess is that it was always assumed that that was the intention of the author as it is hard to believe that anybody would object to line #2 after they agree to line #1 --Jarekt (talk) 11:25, 9 June 2020 (UTC)
- I suggest that we change {{PD-release}} into a warning template. Some people may have added {{PD-release}} planning to use {{PD-self}}, while others may have used {{PD-release}} because it said {{PD-release}} on enwiki without realising that the templates are different. All of these files need to be checked. --Stefan2 (talk) 11:47, 9 June 2020 (UTC)
- I agree, that is strange. In some documentation {{PD-author}} is mentioned as for cases where author is from external website. I noticed we also have a lot of files with {{PD-release}} tag transferred from other projects. At the moment {{PD-release}} redirects to {{PD-self}}. So it seems like the second sentence is added automatically to many PD files even when it is unclear that author did agree to that specific license. My guess is that it was always assumed that that was the intention of the author as it is hard to believe that anybody would object to line #2 after they agree to line #1 --Jarekt (talk) 11:25, 9 June 2020 (UTC)
- I'm not sure that there'd even be many cases where the uploader isn't the author, but the author did agree to that specific license. --ghouston (talk) 02:37, 9 June 2020 (UTC)
- What is strange is that {{PD-self}} is identical to {{PD-author}} except it is for cases where author is the uploader, so {{PD-author}} should be for images where author is not the uploader. Also on other Wikipedia project the template with just the first sentence is called Template:PD-release (Q6208203). --Jarekt (talk) 02:31, 9 June 2020 (UTC)
- It would be better to have a custom template for the Flickr PD-Mark own-work files, if they are going to be accepted, which would explain the assumptions that have been made: that the Flickr uploader is the author, and that they've apparently released it to the public domain. --ghouston (talk) 01:51, 9 June 2020 (UTC)
- --ghouston, I see your point the first sentence "This work has been released into the public domain by its author, {{{1}}}. This applies worldwide." is fine when applied to flickr images released to Public domain by the authors, but the second sentence is more of an issue. The first sentence, applies to US and countries where release to "public domain" is recognized by law and is sufficient to meet requirements of COM:LIC. Maybe in case of the "PD by author" images from flicker we should drop the second sentence as the legal situation in some countries (which countries?) is unclear, or replace it with "In some countries this may not be legally possible, if so than in those jurisdictions the copyright status is unclear". --Jarekt (talk) 17:15, 8 June 2020 (UTC)
- @Jarekt: It’s a complex issue. See Commons:Village pump/Copyright#Double standards for Public Domain Mark. Brianjd (talk) 06:26, 8 June 2020 (UTC)
- I think {{PD-author}} can only be properly used by the author themselves, since it's not possible to grant a license on their behalf, i.e., "{{{1}}} grants anyone the right to use this work for any purpose, without any conditions, unless such conditions are required by law." --ghouston (talk) 10:00, 6 June 2020 (UTC)
- I think, files released on flickr as "Public Domain" are OK on Commons as long as the files were released to public domain by the photographers. "Public Domain" files linking to CC-O are preferable but files linking to Public Domain Mark meet the requirements of COM:LIC policy. We usually add {{PD-Author}} to such files. --Jarekt (talk) 01:03, 6 June 2020 (UTC)
- I would just like to submit the following attempt at clarification, for anyone who might benefit from it, because it seems some people are confused here: "Public domain" is not a license. Licenses depend on copyright existing and being in force for the work; public domain is the absence of copyright. Therefore, if something has been placed in the public domain or has fallen into the public domain, the whole concept of licenses is inapplicable to it. However, some jurisdictions (such as Germany) don't have the concept of the public domain defined in their laws, which is where CC0 comes in. As I understand it, CC0 acts as a public domain dedication (i.e. renouncing copyright and therefore all possibility of licensing) in jurisdictions where the public domain exists, and as a maximally permissive license (simulating the work being in the public domain by giving everyone permission to do anything with it) in jurisdictions where it doesn't. Therefore, using CC0 is preferable to just saying "I dedicate this work to the public domain" in that it is effective in all jurisdictions, not just in those jurisdictions whose laws define the public domain. However, if the public domain is defined in the relevant jurisdiction(s) for a given work, any statement of dedication to the public domain should be sufficient. PointyOintment (talk) 21:19, 10 June 2020 (UTC)
- Thank you. This sums it up pretty nicely. De728631 (talk) 21:27, 10 June 2020 (UTC)
- @PointyOintment: On at least one point here, I believe you are wrong. Germany has a concept of public domain; it is just that under German law you cannot give up your copyright and place a work in the public domain. But, for example, the works of Goethe are certainly now in the public domain in Germany. - Jmabel ! talk 01:00, 11 June 2020 (UTC)
- @Jmabel: Oh, I see. Thank you for the clarification. I have never dealt with any German law, so that was just an example from my memory that I didn't look up to confirm, which I should have made clearer. ← PointyOintment ❬t & c❭ 23:36, 12 June 2020 (UTC)
- @PointyOintment: On at least one point here, I believe you are wrong. Germany has a concept of public domain; it is just that under German law you cannot give up your copyright and place a work in the public domain. But, for example, the works of Goethe are certainly now in the public domain in Germany. - Jmabel ! talk 01:00, 11 June 2020 (UTC)
- Thank you. This sums it up pretty nicely. De728631 (talk) 21:27, 10 June 2020 (UTC)
Damage to category tree by template application of wrong categories, related to Pi bot and Wikidata Infobox confusion
If you look at the first page of subcategories of Category:People by name (which is supposed to only contain categories for named individuals), you'll see a great many categories that shouldn't be there, of the form "<year> in <US state/territory>". (Interestingly, it's only a few states/territories.)
What these seem to have in common is that each one was edited by User:Pi bot (operated by User:Mike Peel) to add {{Wikidata Infobox}}. I don't know if those edits caused the mess immediately, or if it happened later as a result of a change to Template:Wikidata Infobox or a change in how Wikidata handles the infobox's requests.
If you look at Category:1947 in Puerto Rico, for example, the first thing you notice is that there are big red The time allocated for running scripts has expired. messages all over the page. Looking at the infobox (the part of it that's not totally broken, that is), it looks like it's trying to simultaneously be an infobox for an intersection category (1947 ∩ Puerto Rico), an infobox for 1947, and an infobox for Puerto Rico (and maybe an infobox for a fourth thing as well, but it ran into errors). I checked, and Wikidata doesn't seem to have any item for "1947 in Puerto Rico" (as I expected), so maybe that's causing it to get confused? Or, in the infobox-for-an-intersection-category section, it does seem to indicate that it understands that it needs to look at both 1947 and Puerto Rico as separate items, so maybe it's doing that and just going too far with it?
But then, looking at the categories that that category has, I find they are all added by either the Puerto Rico year navigation template or the Wikidata infobox. The first four look like ones that the year navigation template should add, so that's fine. (And checking the older revision of the page, with that template but before the Wikidata Infobox was added, then's nothing wrong then.) But, after those first four, there are several categories that should directly contain only years (or months), and not just ones that would apply to 1947. There are categories for "{Common year|Leap year|Month} starting on <day of week>", all for every day of the week! And then there's a bunch of people categories, "{People|Deceased people|LGBT people|Men|Women} by name", which don't seem to have any connection to 1947 in Puerto Rico, and which bring me back to how I discovered this.
I have no idea what the extent of the damage is, when it occurred, or how it could be fixed, so I thought I'd post here in the hope that people more knowledgeable might take a look. (I'm hopeful that, because the categories are template-added rather than hardcoded into the category pages, it'll be somewhat simpler to fix all at once.) ← PointyOintment (talk) 22:10, 10 June 2020 (UTC)
- I would have thought that the obvious thing to do is to point this out to @Mike Peel: . Rodhullandemu (talk) 22:14, 10 June 2020 (UTC)
- I thought of that at first, but then realized it may not be Mike's (bot's) fault due to the possibility that everything was fine after it made those edits and the mess only happened when some other change was later made elsewhere (to the Wikidata Infobox template, or at Wikidata itself), and so Mike might not have any idea what went wrong. (This is strengthened by the observation that the bot added the infobox template to all of those categories with no parameters, which is the default way of using it according to its documentation.) And have I not effectively notified Mike by linking to his user page above? ← PointyOintment (talk) 22:23, 10 June 2020 (UTC)
- As for the infobox: this seems to be how the infobox handles intersection categories in general. Wikidata even has a constraint against adding an image property to an item for an intersection category. - Jmabel ! talk 01:21, 11 June 2020 (UTC)
- What is the technical definition of "intersection category"? The fact that its Wikidata entry has property P971? -- King of ♥ ♦ ♣ ♠ 01:49, 11 June 2020 (UTC)
- @Mike Peel: This constraint seems strange to me. I recently looked at Meadows in Merseyside to find that the Wikidata item has an image of a Russian meadow. We even have meadows in Liverpool, so why not use a local image for a local category? Senseless! Rodhullandemu (talk) 11:05, 11 June 2020 (UTC)
- As for the infobox: this seems to be how the infobox handles intersection categories in general. Wikidata even has a constraint against adding an image property to an item for an intersection category. - Jmabel ! talk 01:21, 11 June 2020 (UTC)
- I thought of that at first, but then realized it may not be Mike's (bot's) fault due to the possibility that everything was fine after it made those edits and the mess only happened when some other change was later made elsewhere (to the Wikidata Infobox template, or at Wikidata itself), and so Mike might not have any idea what went wrong. (This is strengthened by the observation that the bot added the infobox template to all of those categories with no parameters, which is the default way of using it according to its documentation.) And have I not effectively notified Mike by linking to his user page above? ← PointyOintment (talk) 22:23, 10 June 2020 (UTC)
- There's a performance issue with the infobox that is being sorted out, {{Wikidata Infobox/sandbox}} should resolve it. In particular, the categories are currently added at the end of the infobox code, so if it times out then they all get added rather than just the appropriate ones; these will now be at the start of the template so won't be affected by any remaining timeouts (the rest of the code is also a bit faster). I'll aim to update it this weekend. Thanks. Mike Peel (talk) 07:21, 11 June 2020 (UTC)
- The new version is deployed, that should have resolved this issue. Please let me know if you spot anything else wrong. Thanks. Mike Peel (talk) 17:07, 12 June 2020 (UTC)
- I just did a null save on Category:Meadows in Merseyside, and it looks fixed. @Mike Peel: Thank you! -- King of ♥ ♦ ♣ ♠ 19:05, 12 June 2020 (UTC)
- Thanks, but it's fixed only up to a point. The Russian meadow is gone, but there is still a conflicts-with constraint error when I add an image of a meadow in Liverpool. Rodhullandemu (talk) 19:22, 12 June 2020 (UTC)
- @Rodhullandemu: I suggest raising it at d:Wikidata:Project chat. The infobox will display the image if it's present, it's up to the community to decide if 'category combines' articles should have images. Thanks. Mike Peel (talk) 19:31, 12 June 2020 (UTC)
- Thanks, but it's fixed only up to a point. The Russian meadow is gone, but there is still a conflicts-with constraint error when I add an image of a meadow in Liverpool. Rodhullandemu (talk) 19:22, 12 June 2020 (UTC)
- I just did a null save on Category:Meadows in Merseyside, and it looks fixed. @Mike Peel: Thank you! -- King of ♥ ♦ ♣ ♠ 19:05, 12 June 2020 (UTC)
- The new version is deployed, that should have resolved this issue. Please let me know if you spot anything else wrong. Thanks. Mike Peel (talk) 17:07, 12 June 2020 (UTC)
Copyright situation of maps from Mars created with Redmapper
Are here people who know and have an account in RedMapper and can add some info to Commons:Deletion requests/File:Babakin crater.jpg? — Speravir – 23:26, 12 June 2020 (UTC)
Change The Traditional Chinese logo of Chinese Wikipedia's svg verson to New verson
See w:zh:Special:PermanentLink/59977854#繁体中文 and phab:T254467, the traditional chinese logo of chinese wikipedia changed, but because of the protect, we couldn't upload new verson.Could someone upload?--Sunny00217 (talk) 02:43, 13 June 2020 (UTC)
- @Sunny00217: I don't read Chinese, so I cannot work out where to obtain the actual SVG file (rather than a thumbnail of it) to do this. - Jmabel ! talk 16:39, 13 June 2020 (UTC)
- @Jmabel: The old version is File:Wikipedia-logo-v2-zh.svg, the new version (per the Phab task, in English) is File:Wikipedia-logo-v2-zh-hant-expected.svg. --AntiCompositeNumber (talk) 18:12, 13 June 2020 (UTC)
- @Sunny00217: @AntiCompositeNumber: Done, please verify. - Jmabel ! talk 18:22, 13 June 2020 (UTC)
- @Jmabel: The old version is File:Wikipedia-logo-v2-zh.svg, the new version (per the Phab task, in English) is File:Wikipedia-logo-v2-zh-hant-expected.svg. --AntiCompositeNumber (talk) 18:12, 13 June 2020 (UTC)
Wikidata redirects won't show in the "files depicting" search result
If a media has an item in the "Item portrayed in this file" in the Structured Data section of its page then the item is merged into another item in Wikidata, the search result won't show the media with the redirect and duplicate items will be allowed to be entered in the "Items portrayed in this file". For example, File:Masjid_ar-Rahman_2018-03-21.jpg has two items (Q52002082 and Q20461418) one of which is just a redirect to the other. If only Q52002082 is in the "Items portrayed in this file", the search result will not display it. — Jeluang Terluang (talk) 04:19, 13 June 2020 (UTC)
Images from Unsplash
While working with the categories "Media needing categories as of ...." I see many Images from Unsplash. A problem is that in many cases the file name and the desciption contain the name of the author and nothing about what you see on the photo. In the description is a subject "categories" that gives very general names such as nature, objects and people, buildings and electric. I fear that from the more than 25000 images in the category Unsplash, images without a proper category will never be used or found using a search. An idea may be that a bot takes all images without a category and add the names mentioned in the categories field in the description (if these names exist as category in Commons). Wouter (talk) 21:08, 11 June 2020 (UTC)
- Those categories are pretty vague. I would be in support of using a bot to try to sort them anyway, since that at least gets them into the category tree so users can diffuse them, but in the past I've gotten flak from people for bot-uploading into categories that are too general. If we can muster up consensus I can write the bot. – BMacZero (🗩) 22:55, 11 June 2020 (UTC)
- An easy sort is by photographer. If you set a threshold, say more than 20 images, then subcategories for each photographer would be useful and would be likely to cluster photographs by theme, as most photographers have thematic interests. Example Category:Photographs by Chris Barbalis
- It also makes sense to keep all Unsplash photos in a bucket category (which I think they all still are), this helps when searching for category intersections. Fæ (talk) 08:30, 12 June 2020 (UTC)
- Yes, {{Unsplash}} sets the hidden category Images from Unsplash. Brianjd (talk) 11:39, 12 June 2020 (UTC)
- I think that categories of photographers is a very good idea. Adding the categories of the main themes of the photographer makes the pictures easier to find. I did it with the above given Category:Photographs by Chris Barbalis. Wouter (talk) 18:56, 12 June 2020 (UTC)
- I disagree with that change. Look at Category:Buildings; its a bunch of very general subcats, and suddenly Category:Photographs by Chris Barbalis pops up out of nowhere. Does that look like a reasonable category scheme? -- King of ♥ ♦ ♣ ♠ 19:03, 12 June 2020 (UTC)
- @King of Hearts: Let’s rename it to Category:Photographs of buildings by Chris Barbalis and put it under Category:Photographs of buildings. Does that solve the problem? (After I wrote this, I decided the answer is “no”: for many of the files in this category, it is a stretch to describe them as photographs of buildings and at least one of them does not seem to depict a building at all!) Brianjd (talk) 08:18, 13 June 2020 (UTC)
- I'm with King of Hearts here. What happens once we do that on hundreds of photographers? Also: this makes work by Unsplash photographers way more visible than work by our own contributors. - Jmabel ! talk 00:57, 13 June 2020 (UTC)
- Meanwhile at WM: Bots SDC-tag every medium at commons by author (photographer) with SDC-tags that are meant to supercede categories, but it is not even mentioned in this discussion. --C.Suthorn (talk) 03:32, 13 June 2020 (UTC)
- @C.Suthorn: Is this referring to the “structured data” thing? It looks like some overly formal thing designed for librarians. It will need to get much easier to use if it is going to supersede categories. Brianjd (talk) 08:18, 13 June 2020 (UTC)
- categories are for librarians. SDC tags are an easy access for the laymen, I think user:Keegan (WMF) can elabore on this. --C.Suthorn (talk) 10:27, 13 June 2020 (UTC)
- @Jmabel: Hundreds of photographers? Then how about Category:Photographs of buildings by photographer? About Unsplash contributors/Commons contributors, there may well be some overlap between these sets. I don’t see why it matters anyway. Brianjd (talk) 08:18, 13 June 2020 (UTC)
- The main problem I have is that there are images in Unsplash that do not have a category and that the file name or description does not enables to know what is on the image. Only looking at the individual image makes it possible to give it a general category, because it is not clear where the photo has been taken and what exactly the subject is. What I have seen is that many images are “artistic” which makes it even more difficult to give the right categories. I am not in favor to rename Category:Photographs by Chris Barbalis because it contains more than images of buildings. A solution would be to use Cat-a-lot to add the category “Buildings” or “Graffiti” or “Windows”. For me it would mean to add Category:Images from Unsplash on my watch list and treat each new category “Photographs by …” with Cat-a-lot. The “problem” is that many images in Unsplash are of high quality, otherwise I would leave them “in the dark”. Wouter (talk) 08:58, 13 June 2020 (UTC)
- @Brianjd: Better than the initial approach, but normally we don't do non-user categories by photographer unless the photographer is notable, e.g. Category:Photographs by Anders Beer Wilse. Even there, we don't usually intersect that with subject matter unless the same photographer did a lot of some one thing (e.g. Category:Black and white group portrait photographs at the Alaska-Yukon-Pacific Exposition by Frank H. Nowell. Again, I would object to giving a prominence here to Unsplash photographers that we don't give to our own people. - Jmabel ! talk 16:34, 13 June 2020 (UTC)
- @Wouterhagens: Clogging up very general categories like Category:Buildings isn't the best solution, either. Either these should go in categories like Category:Unidentified buildings or just in maintenance categories analogous to Category:Images from the Seattle Photographs to check. - Jmabel ! talk 16:34, 13 June 2020 (UTC)
- The main problem I have is that there are images in Unsplash that do not have a category and that the file name or description does not enables to know what is on the image. Only looking at the individual image makes it possible to give it a general category, because it is not clear where the photo has been taken and what exactly the subject is. What I have seen is that many images are “artistic” which makes it even more difficult to give the right categories. I am not in favor to rename Category:Photographs by Chris Barbalis because it contains more than images of buildings. A solution would be to use Cat-a-lot to add the category “Buildings” or “Graffiti” or “Windows”. For me it would mean to add Category:Images from Unsplash on my watch list and treat each new category “Photographs by …” with Cat-a-lot. The “problem” is that many images in Unsplash are of high quality, otherwise I would leave them “in the dark”. Wouter (talk) 08:58, 13 June 2020 (UTC)
- Meanwhile at WM: Bots SDC-tag every medium at commons by author (photographer) with SDC-tags that are meant to supercede categories, but it is not even mentioned in this discussion. --C.Suthorn (talk) 03:32, 13 June 2020 (UTC)
- I disagree with that change. Look at Category:Buildings; its a bunch of very general subcats, and suddenly Category:Photographs by Chris Barbalis pops up out of nowhere. Does that look like a reasonable category scheme? -- King of ♥ ♦ ♣ ♠ 19:03, 12 June 2020 (UTC)
- Discussion went on a bit of a tangent. Having Unsplash photographer categories where the photographer has a lot of photos, does not replace other "topic" categories, it just means if you see a photo you like about a topic, then you can easily navigate to other photos by that same person, thereby probably find others you like or might want to use. As a suggestion it's only a small part of improving categorization.
- Using the simple approach of using the bucket category and a keyword filter, is also a way to think about enhancing categorization of this collection. For example if you have some interest in species categories the search incategory:Images_from_Unsplash insect currently has several photographs of insects which are not in any insect related category. Fæ (talk) 10:51, 13 June 2020 (UTC)
- From what I can see, there’s some disagreement about what to do with Category:Photographs by Chris Barbalis, but everyone seems to agree that having it in the subject categories is a problem, so I have removed them. Brianjd (talk) 07:21, 14 June 2020 (UTC)
- I found a solution to solve to some extent the problem. When I encounter an image in "Media needing categories as of ...." with only the author name in the file name and in the description, I use the search option Fæ was mentioning "incategory:Images_from_Unsplash author name". With that selection it is easier to add categories. Wouter (talk) 11:38, 14 June 2020 (UTC)
This courtesy DR could use independent input. After I objected to the courtesy deletion, the uploader claimed that Commons doesn’t respect the wishes of creators. Was I too harsh? Brianjd (talk) 09:44, 14 June 2020 (UTC)
Why do Wikidata Infoboxes not always show up in Commons categories?
I have created categories where the Wikidata infoboxes do not show up. For example Category:Geneviève Goëtzinger. The link to the Wikipedia has been created from the wikidata, but the year of birth has not been added as category. Other examples Category:Istiván János and Category:Bắc Ninh High School for the Gifted. Do I have to wait longer before the box is there or is there an other cause? Wouter (talk) 08:20, 20 June 2020 (UTC)
- You just have to add {{Wikidata Infobox}}. Or wait for a Bot to do so. --Raugeier (talk) 08:28, 20 June 2020 (UTC)
- Thanks, I had forgotten in those cases to add {{Wikidata Infobox}}. Wouter (talk) 09:01, 20 June 2020 (UTC)
- This section was archived on a request by: Jmabel ! talk 14:25, 20 June 2020 (UTC)
Potential huge mess, how to deal with it?
What do you think? Am I too fastidious here?
There is File:Standard Model of Elementary Particles.svg, originally created by MissMJ in 2008 and licensed under CC 3.0 – and it is quite often used. This file has a lot language derivations. I wondered why they look different in apparently two modes and noticed that on 22 June 2013 Cush uploaded a new version, which in my opinion is against COM:OVERWRITE, and also changed the license to CC 1.0. The same happened for some language versions. Not enough Cush created derivatives without mentioning this – at least as source, probably original author; but the derivations are from the own altered version – in these:
- File:Standard Model of Elementary Particles + Gravity.svg
- File:Standard Model of Elementary Particles Anti.svg
- File:Standard Model of Elementary Particles Gravity Hadron.svg
- File:Standard Model of Elementary Particles dark.svg
- File:Standard Model of Elementary Particles and Gravity.svg
Shouldn’t the overwrite better split into a new file? How to deal with the licenses? And allow the sources as indicated by MissMJ a CC licensing? Are the derivatives worth to be counted as own work of Cush (as long the original source would be mentioned)? Who should fix all this if I am right? — Speravir – 22:52, 3 June 2020 (UTC)
- PD releases of derivative works don't need to be deleted, as it allows anyone to change the license to something that actually complies with the original terms. -- King of ♥ ♦ ♣ ♠ 23:12, 3 June 2020 (UTC)
- Just to be clear I have no intention that there should something be deleted, because I think everything could be fixed. — Speravir – 23:25, 3 June 2020 (UTC)
- The file "Standard Model of Elementary Particles.svg" was originally created by MissJ, and her choice of license made use of her artwork subject to said license. The license for her contribution is retained because the newer chart is not available in all languages yet. The newer chart uses a different artwork while only the colors for the particle groups were adapted from ZooFari's edits. Over time, the SVG structure of the new chart has been changed from using outlines to solely using fonts, while retaining the visual appearance for usual browsers and rendering-engines. I have released my artwork into the public domain to make use and improvement by third parties easier. @Speravir what kind of fix do you have in mind? Cush (talk) 15:32, 4 June 2020 (UTC)
- Btw, the changes to the original artwork to adjust measurements of mass etc were done by numerous other editors before I restored the appearance as in AnonMoos' version (the weird 3d-blocks look was not by MissJ), and before I later fully changed the design. The overhaul of the internal SVG structure was done by Glrx, who removed the outlines that used to represent the uncommon fonts previously used. Cush (talk) 15:44, 4 June 2020 (UTC)
- @Cush: First of all: I was wrong in one point – MissMJ chose CC 3.0, not CC-by-SA 3.0, so opting for a different license was allowed, sorry for confusing this. Then: Your sentence “The newer chart uses a different artwork” is exactly why I am convinced this never should have uploaded under the same name! The following “while only the colors for the particle groups were adapted from ZooFari's edits” is exactly the reason why you should have mentioned that this and after this all of these are derivations; this sentence and the following words are the reasons why the original file should have mentioned as source.
- What kind of fix do I have in mind?
- Request a split in COM:HMS between versions from 20 June 2013 by AnonMoos and the first from 22 June 2013 by you, Cush. Choose an appropriate name yourself. (Add “light coulours”?)
- Then the file usages have to be checked and very probably in most cases switched to the new file. I could help you here, but for some usages we may need administrators.
- Add for the new and every other file listed above, that this is a derivation (template {{Derived from}}) and add the original file as source (both can be combined, but this is optional). If you consider your own work more than technical handwork you can leave you as author, otherwise you should add at least MissMJ (but, yes, then all other editors would in strict sense have to be mentioned, as well).
- For the files in different language a similar approach is necessary, but this must be checked individually: There was at least one file that was only uploaded in your design.
- Make an update of the other versions gallery.
- Maybe I even forgot something. — Speravir – 18:07, 4 June 2020 (UTC)
- That seems quite complicated. How is the split achieved? Just by posting in COM:HMS and then some bot will perform the split? How are the references updated, or are they then targeting the previous file version? Cush (talk) 10:42, 8 June 2020 (UTC)
- I take the silence as a sign of absent interest in the matter. I would not proceed with the split for now, and rather wait until MissMJ contacts me. Cush (talk) 20:27, 15 June 2020 (UTC)
SVG upload
Hi, I'd like to upload a SVG file that already exists on Commons, but I translated it into German for a wiki article. But the upload does not work, I keep getting this error message: "This file contains HTML or script code that may be erroneously interpreted by a web browser". Please note that the revised file will be displayed correctly in all common browsers (MS IE, Firedox, Safari). What is going on? Who can help me? Best regards, Mosbatho (talk) 13:20, 14 June 2020 (UTC)
- Mosbatho, einmal Fragen hätte ausgereicht, entweder hier oder in COM:Forum. In letzterem gibt es jedenfalls weitere Antworten. — Speravir – 01:07, 15 June 2020 (UTC)
- Speravir thank you for your hint. I wonder why you mix in this issue? hmm. --Mosbatho (talk) 14:38, 15 June 2020 (UTC)
Jmabel, thank you for help but the Germans on COM:FORUM mentioned that there might be no need for such a file. Thank you. Bye, Mosbatho (talk) 14:42, 15 June 2020 (UTC)
- @Mosbatho: That is fine; you didn't ask whether such a file was desirable, you asked a technical question, which I answered. - Jmabel ! talk 15:44, 15 June 2020 (UTC)
Results of centralized discussion on standardizing format of COVID-19 maps
At en-WP's COVID-19 WikiProject, we recently held a discussion on standardizing the format of COVID-19 maps (e.g. cases, deaths, recoveries, etc.). The discussion has now been archived and came to these conclusions:
- There is no consensus about which color schemes to use, but they should be consistent within articles as much as possible. There is agreement that there should be six levels of shading, plus gray (#cdcdcd) for areas with no instances or no data. Link 1, Link 2
- There is no consensus about whether the legend, the date, and other elements should appear in the image itself. Link 1, Link 2
- For map legends, ranges should use fixed round numbers (as opposed to updating dynamically). There is no consensus on what base population to use for per capita maps. Link 1, Link 2
I would say that further discussion is needed to try to reach consensus on these matters, and Commons is probably a better place to hold it than Wikipedia given that maps are multilingual. Anyone who wants to organize such discussion, please feel free to do so. Regards, Sdkb (talk) 01:25, 16 June 2020 (UTC)
This is an interview by a notorious activist, Maryam Namazie, of two notorious Femen activists, Aliaa Elmahdy and Amina Tyler, before a notorious Femen protest in Paris. The video was initially nominated to be the MOTD on 6/2. A user raised at AN a concern of "nudity" as the breasts of Elmahdy and Tyler are showing : Commons:Administrators' noticeboard/Archive 80#nudity on front page. There was no consensus it was a valid argument. In the course of the discussion user:King of Hearts moved the file to be the MOTD for 6/18. A parallel discussion was started on Commons:Village_pump/Proposals#Turn_MOTD_into_MOTW which also led to no conclusion. I recently realized King of Hearts had replaced the MOTD for 6/18 with another file and reached out to them to propose two other dates at User_talk:King_of_Hearts#MOTD. Their opinion is the file should not be a MOTD because it is too blurry. My opinion is we should not give too much weight to such technical considerations if a document has a high educational content, as our mission is to document our educational projects and the blur here is part of the intrinsic nature of the original document and cannot be replaced with a non blurry version. Pinging the editors who contributed to the discussion at AN and VP: Jahobr, Fæ, Rodrigo.Argenton, Taivo, Iridescent, DMacks, Ricky81682, Mike Peel, Pi.1415926535, Cuatro Remos, 4nn1l2, Jarekt, Roy17, Donald Trung, Tiven2240. Apologies if I forgot someone. — Racconish 💬 19:34, 15 June 2020 (UTC) @123uhjsakddsa89321l3: 19:37, 15 June 2020 (UTC)
- Personally I would say that the main page should try to be as educational as possible, while higher qualities should at all times be preferred, when one day other videos from the John F. Kennedy assassination will enter the public domain then I'd rather have a blurry video of that event, then a high quality video of let's say the same butterfly or moth for three (3) days. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:43, 15 June 2020 (UTC)
- Just to note that this video was added to a MOTD template a new user who only made 6 edits, see Commons:Administrators'_noticeboard/Archive_80#nudity_on_front_page. I've now blanked the three other MOTD creations by that user (Template:Motd/2020-08-02, Template:Motd/2020-09-02 and Template:Motd/2020-12-02). Apart from pointing out that the user was probably trying to cause controversy, I have no other comment to make here. Thanks. Mike Peel (talk) 19:48, 15 June 2020 (UTC)
- In my opinion, "historical/educational value" is primarily a consideration for works that are notable in their own right. We have lots of other non-notable videos of interviews with notable people on Commons. Of all the ones we could possibly feature on the Main Page, is this one really the best we have to offer? -- King of ♥ ♦ ♣ ♠ 20:53, 15 June 2020 (UTC)
- user:King of Hearts spoke of a defacto prohibition of nudity on the front page in an archived discussion.
- File:12-03-17-aktstudien-nuernberg-by-RalfR-32.jpg POTD 1. feb 2016, used in it:Nudità
- File:Nude recumbent woman by Jean-Christophe Destailleur.jpg POTD 8 jun 2018, used in lt:Erotika
- File:Women model top.jpg POTD 27 sep 2018, used in pl:Ciało_ludzkie#Ciało_ludzkie_w_sztuce_a_pornografia
- all this files were POTD, shown on many language versions of wp on the front page and in the wp app as POTD. The video of the day is only shown at the commons front page and nearly nobody knows about commons, and those who do, do not look at the front page. --C.Suthorn (talk) 21:00, 15 June 2020 (UTC)
- The topic (feminism) is interesting. The interviewees are public figures. But this interview is really boring. They look rather unmotivated themselves.
- I suggest replacing it, with File:Mysimpleshow Transfer 1 Why is Feminism Necessary .webm maybe.--Roy17 (talk) 21:07, 15 June 2020 (UTC)
- I have a few comments:
- The MotD notice on this file contains a description that clearly belongs to a different file. Someone messed up here, but I haven’t investigated this.
- There doesn’t seem to be any criteria for MotD, other than the personal opinion of each user who bothers to discuss it. The closest thing to a criterion is the PotD criterion that PotD must be FP, but applying this to MotD might be problematic (I think this issue was raised in the MotW discussion).
- The general principle seems to be that once a (P|M)otD has been proposed, no one should remove it unless there’s a clear reason to do so (and I can’t see a clear reason here). If this statement is not correct, then this needs to be documented somewhere.
- Acknowledging the ping, but my only input to the previous discussion was to point out (in my capacity as an en-wiki admin) that the assertion that English Wikipedia maintains a blacklist of images deemed inappropriate for the main page was untrue and based on a misunderstanding. (The blacklist does exist, but is of images that don't have sufficient accompanying text to provide a context, not of images which we've decided need to be censored; we've run both borderline pornography and graphic imagery of crime scenes when we have appropriate encyclopedic grounds to justify it.) I have no strong opinion on what runs as MOTD here, other than to say that this particular file seems fairly uninteresting and of poor quality. — iridescent 13:50, 16 June 2020 (UTC)
Images d'actes sexuels : contenu éducationnel?
Bonjour, j'espère être au bon endroit pour poser ma question. J'ai lu [[2]] mais n'ai pas trouvé de réponse claire.
Y a-t-il des règles et recommandations à ce sujet (sexe/ éducationnel) quand des adolescentes (teens) sont représentées dans les actes sexuels? Est-ce que ça dépend de l'âge de consentement du pays ou de la nationalité des participantes? Formule cordiale, --Msbbb (talk)
- I would say that if there is any serious doubt about the legality of a photo on this basis in either the country where it was taken, or the U.S. where we are hosted, we shouldn't have it. - Jmabel ! talk 16:49, 12 June 2020 (UTC)
- The US law as the hosting country is the most important to understand. Nudity of itself is not sexual, though every legislation has struggled to define in law what an image of a "sexual act" is. Rather than debating hypotheticals, anyone wanting to refine policy or guidelines should consider examining past deletions, both with keep or delete outcomes, and use these as a possible case book to justify any changes. With the forthcoming WMF UCOC, there may be scope at that time to have another discussion about implementation in relevant cases, which may include further limiting the types of content considering in scope for this project... Expect a long debate. --Fæ (talk) 17:00, 12 June 2020 (UTC)
- Bonjour, merci de vos réponses. Je ne parle pas de nudité, mais de scènes de sexe, de photos avec une légende "pour faire un film pornographique amateur", avec en légende " ... and teen". Et ces photos peuvent se retrouver en illustration sur, par exemple, les wiktionaries. C'est vrai aussi que "teen" va de 13 à 19 ans et qu'il est facile d'indiquer n'importe quel âge dans la légende, pour être en conformité avec les lois des É-U (Depending on the jurisdiction, the legal age of consent is between 16 and 18). Dans les discussions sur le WMF UCOC sur Wikipédia, je n'ai pas vu de référence à ce genre de question. Bref, attendre.... --Msbbb (talk) 04:49, 17 June 2020 (UTC)
Using different Wikipedia projects as a loophole to protect hoaxes
This is regarding Commons:Deletion requests/File:Average East-Eurasian ancestry (Mongoloid).png. @Gestumblindi: closed this based on COM:INUSE.
I have two questions:
- Is the only way to delete this false information to go to each individual page on multiple projects, and to try and explain that this information is false, in multiple languages I don't speak?
- Right now, this is a loophole that preserves hoax info by included it in smaller Wikipedias. What options are there to deal with this loophole?
This image is a hoax. The information was derived from a very similar hoax image uploaded by a globally-blocked sock puppet. This is also supported by this deletion request. Based on this overlap, all of these images were uploaded for disruptive purposes.
False information is not educational, so this is not merely a content dispute. The information in this chart is explained in English and no other language, but is used on different language projects. This image was added to dozens of project by either an IP which has been blocked for sock puppetry on multiple projects, or obvious sock puppet accounts of this same known disruptive editor. Again, several of these accounts have been globally blocked.
This editor has a history of lying about their personal background, so there is no reason to think this editor even speaks the same language as most of these Wikipedia projects.
Thanks. Grayfell (talk) 05:02, 16 June 2020 (UTC)
- Yes.
- Yes. None that is effective.
- Commons is a massive loophole if you want to spread fake "genetic" race theories.
- You might hope that the WMF UCoC might help, but it will not solve this.
- Unfortunately the standard mantras of "not censored" and "in use", make even highly specific proposals to get rid of even the most blatant racist fake news conspiracy trash, impossible.
- Sorry, I have no idea how to make this better and it is bizarre considering that conspiracy fakenews being spread around Wikimedia projects and fueled by Commons images or data, instead of educational images, directly damages the educational content of this project, going against COM:Scope. Fæ (talk) 08:24, 16 June 2020 (UTC)
- The problem gets even worse when perpetrators have links to admins on small wikis. When that happens no one is able to get rid of it on the small wiki. Attempting to do so is gonna get you blocked.
- I come across one such trouble for the past two years. A few days ago I just happen to raise a similar question on wikidata: d:Wikidata:Project_chat#Need_help_and_advice_on_how_to_deal_with_self_promotional_SPAM_on_a_small_wiki.
- I believe one thing WMF should really adopt is limited terms for any advanced user right on small wikis. Not small should be defined as active (monthly edit>100) editors>100 for an entire year.
- When they dont get perpetual admin right, maybe it'd be more difficult to control a small wiki and cover up all the spam, hoaxes, self promotion, advertisements, etc.--Roy17 (talk) 08:48, 16 June 2020 (UTC)
- I've added an illustration above of how one way of handing blatant fake news would be to add a warning notice to the image, and gain a consensus to use that as the current version. This would delete or "censor" nothing, but does add to the educational value per COM:Scope by correctly identifying fake news as such, along with making that clearer where used on Wikimedia projects. --Fæ (talk) 08:55, 16 June 2020 (UTC)
- Your method is just feeding the trolls. Bad publicity is still publicity.--Roy17 (talk) 09:00, 16 June 2020 (UTC)
- Everything about [[:|your illustration]] worries me:
Did you just make this up as a way of demonstrating the warning? People who come across this file won’t know this – they will think the warning is real. That creates its own problems.(see below)- For the files where we actually want a warning, I would say that they fall into one of two cases:
- They are clearly incorrect, and there is no reasonable objection to the claim that they are incorrect. In that case, they probably have no educational use and so should be deleted.
- Things are not so clear. In that case, don’t add a warning that claims that things are clear.
- Brianjd (talk) 09:03, 16 June 2020 (UTC)
- I just realised that you didn’t pick a random file; it’s the one subject to the DR linked above. But that DR doesn’t clearly indicate that the information is false, so my objection to this warning, as well as similar warnings on other files, stands. Brianjd (talk) 09:05, 16 June 2020 (UTC)
- Whenever you read about modern theories of "Mongoloid" race or genetics it is fake news racist rubbish. This is not the least bit unclear, and there's nothing here for me to "prove" before adding a warning sign that it's crap. Refer to Mongoloid#In_the_context_of_scientific_racism. --Fæ (talk) 09:09, 16 June 2020 (UTC)
- I didn’t do any background reading, and the target audience for your warnings won’t do any background reading either. You need to put that information clearly on the file description, where it belongs. And if it’s so clear, why can’t we override the policy about COM:INUSE (I don’t have time to think about this now, might need further discussion) Brianjd (talk) 09:30, 16 June 2020 (UTC)
- Whenever you read about modern theories of "Mongoloid" race or genetics it is fake news racist rubbish. This is not the least bit unclear, and there's nothing here for me to "prove" before adding a warning sign that it's crap. Refer to Mongoloid#In_the_context_of_scientific_racism. --Fæ (talk) 09:09, 16 June 2020 (UTC)
- I've added an illustration above of how one way of handing blatant fake news would be to add a warning notice to the image, and gain a consensus to use that as the current version. This would delete or "censor" nothing, but does add to the educational value per COM:Scope by correctly identifying fake news as such, along with making that clearer where used on Wikimedia projects. --Fæ (talk) 08:55, 16 June 2020 (UTC)
- @Grayfell: a trick for getting rid of these hoaxes while not giving them undue attention: com:copyvio. This map should specify its base map but it does not, so tag it with {{Dw-nsd}}.--Roy17 (talk) 09:00, 16 June 2020 (UTC)
As I received a ping here: As a Commons admin, I usually see no leeway in handling COM:INUSE and COM:NPOV, if there are no copyright concerns. I truly regret this sometimes, but if we didn't handle matters this way, Commons would become a "loophole" of the other kind: People could try to settle their subject matter disputes by skipping their (Wikipedia) project discussion and get material deleted on Commons. Actually, that's what is often attempted and prevented by COM:INUSE. That's why Commons has this rule. We don't want to become the ersatz battlefield for people debating a topic in their local project.- But if it must be assumed that File:Average East-Eurasian ancestry (Mongoloid).png was taken from some external source without a suitable license, or has a copyrighted map as a base, then we could delete it for that reason, of course (and then also the modified copy with warning notice [[:]] which was now made and is displayed here). You could always file a new deletion request based on this. (Note: It's the original file that's still widely in use, not the copy with warning someone has embedded as a thumbnail here). Gestumblindi (talk) 09:47, 16 June 2020 (UTC)
- I think we may need a policy prohibiting media spreading racist and conspiracy agendas without a critical (educational) comment on them. Indipendent of the usage in any other project. This is also needed to protect the values of the project, the UN SGDs and sometimes even the human rights. --GPSLeo (talk) 10:06, 16 June 2020 (UTC)
- @GPSLeo: I guess that just raises questions like “what is racist?” and “what is a conspiracy agenda?” (before you scream that the answers are obvious, note that if the answers really were obvious, then we wouldn’t be having this discussion to begin with) And bringing critical commentary into Commons would surely introduce its own issues. It sounds like the first step to turning Commons into Wikipedia. Brianjd (talk) 10:21, 16 June 2020 (UTC)
- Of course these topic is not easy and discussions will be complicated. But I think we need to face these problems to protect our project, we can not always say that the other projects need to solve this themselves, we are already more than just the file hosting platform. Every file description, every category and the files in it and especially every gallery page (can) include a political statement. --GPSLeo (talk) 10:49, 16 June 2020 (UTC)
- @GPSLeo: I guess that just raises questions like “what is racist?” and “what is a conspiracy agenda?” (before you scream that the answers are obvious, note that if the answers really were obvious, then we wouldn’t be having this discussion to begin with) And bringing critical commentary into Commons would surely introduce its own issues. It sounds like the first step to turning Commons into Wikipedia. Brianjd (talk) 10:21, 16 June 2020 (UTC)
- Though a speedy deletion tag would be convenient, as there has been a DR on the map in question, this is not right by policy. For this reason Commons:Deletion_requests/File:Average_East-Eurasian_ancestry_(Mongoloid).png has been raised, even though the last DR was recent. The facts of the nomination are different to the last DR, and are not addressed by the last closure statement. --Fæ (talk) 12:13, 16 June 2020 (UTC)
- Separately and more generically I have (for a second time) raised the issue of Wikipedia promoting Scientific racism in multiple languages, of which this map is a symptom. Refer to (Wikimedia-l) Promotion of scientific racism in Wikipedia articles. Sadly, apart from me getting trolled off-wiki by the usual idiots, I suspect that no action will be taken, as this was exactly the same last year. --Fæ (talk) 13:11, 16 June 2020 (UTC)
Update: As flagged in the deletion request, within minutes of upload of this file, an anon IP account inserted the file into 14 different language Wikipedias, and multiple articles on each Wikipedia, within 40 minutes. Which is a sophisticated user going out of their way to promote this image (and the title "Mongoloid"). All global usage of this file is down to the manipulation by this IP account.
This is the deliberate and successful manipulation of Commons deletion policies. --Fæ (talk) 10:15, 17 June 2020 (UTC)
Widely used picture with no author information
File:Pistacia lentiscus.jpg is used in almost 40 different Wikipedias, but it has no author nor source information. Is this a problem? Should the Wikipedias stop using it? And, less importantly, should I not use this picture in my school presentation due tomorrow? Thanks! 177.38.105.181 19:54, 16 June 2020 (UTC)
- It has a reasonable resolution (especially for the year when it was created per Exif data, 2001) and full Exif camera data. I would therefore assume "own work" by the uploader User:Lumbar~commonswiki. At the time when it was uploaded, early 2005, own works were often uploaded without an explicit "own work" statement (that's how the original description page looked). I would see it as a kind of grandfathered file, although the Commons:Grandfathered old files policy is dealing with another kind of "grandfathering" (releases for files created by third parties). To suppress the irritating "lacking source" and "lacking author" messages, we maybe could enter something like "Own work assumed". - Anyway, I see no problem with you using the picture in your school presentation! Gestumblindi (talk) 20:03, 16 June 2020 (UTC)
 Done Template fixed. Ellin Beltz (talk) 20:08, 16 June 2020 (UTC)
Done Template fixed. Ellin Beltz (talk) 20:08, 16 June 2020 (UTC)
- @Ellin Beltz: Mixing a localised template with a non-localised message, as in {{Own}} assumed, seems like a bad paractice. There should be a template for “Own work assumed”; I’m surprised we don’t have one. Brianjd (talk) 11:35, 17 June 2020 (UTC)
- We do have {{Own assumed}}. But that’s supposed to be for cases where the uploader has explicitly stated they are the copyright owner, and we just need to fix the source. I don’t know whether we should use it here. Brianjd (talk) 11:39, 17 June 2020 (UTC)
- @Ellin Beltz: Mixing a localised template with a non-localised message, as in {{Own}} assumed, seems like a bad paractice. There should be a template for “Own work assumed”; I’m surprised we don’t have one. Brianjd (talk) 11:35, 17 June 2020 (UTC)
Displaying/downloading filenames under a specific category
Hi all, is there a tool to list all the files under a specific category? I'm trying to download the filenames of all the files of a specific category but haven't been able to find a tool to do that. Any help will be really appreciated. --Psubhashish (talk) 13:06, 17 June 2020 (UTC)
- UPDATE: Looks like I've found a solution using Petscan. --Psubhashish (talk) 14:42, 17 June 2020 (UTC)
Wikidata infobox in hidden administrative category
yes or no? --C.Suthorn (talk) 05:42, 15 June 2020 (UTC)
- Your question is unclear; please don't make us try to guess. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 13:06, 15 June 2020 (UTC)
- I would have thought the question can not be any clearer. But then: a bot adds the wikidata info template to a hidden adminstrative category. The category happens to be my user category, that I use to organize my work and as a "business card" of sorts, when trying to beg for a accredtion to an otherwise closed event. It is unsettling not to know how this business card will look like at the moment a host of en event will read the message that I did sent. --C.Suthorn (talk) 14:32, 15 June 2020 (UTC)
- I would not think a user category should have a Wikidata item, let alone a Wikidata Infobox. We don't give Wikidata items to users, unless they are otherwise notable. Why to user categories? Did you build the Wikidata item yourself to get interwiki links, or did someone else build it? - Jmabel ! talk 15:59, 15 June 2020 (UTC)
- Creator:-Entrys are filled from wikidata. Therefore there is a Creator-Wikidata-Item. A link from wikidata to commons can be included to or deleted from anyone at wikidata at will. Even if i remove that link, a bot at wikidata may add it again.
- Why are wikidata info templates are added at all (and by bot edits). Just have the wikidata info template in the css of category pages (and make it invisible in hidden cats). No more bot edits needed. --C.Suthorn (talk) 17:14, 15 June 2020 (UTC)
- The problem is the infobox at Category:Files by C.Suthorn? I think it looks quite good, but could do with expanding. I'm not aware of any way that the infobox could be added by css rather than by bot. Thanks. Mike Peel (talk) 18:47, 15 June 2020 (UTC)
- Again, though, why does {{Creator:C.Suthorn}} exist? I don't remember there ever being a consensus to set things like that up for normal Commons contributors. In fact, rather the contrary: while Commons:Creator has never been formally adopted, I believe it reflects more of the thinking here than not, and among the listings for who should not have a "creator" page, "Wikipedia and Commons users, as well as photographers from image-hosting websites, like Flickr, who do not meet notability criteria. Many such templates are autobiographical, and there are no proper sources to support any of the facts, other than other autobiographical sources. The usual practice is to use username with a link to customized user's page in the author field." - Jmabel ! talk 02:40, 16 June 2020 (UTC)
- The problem is the infobox at Category:Files by C.Suthorn? I think it looks quite good, but could do with expanding. I'm not aware of any way that the infobox could be added by css rather than by bot. Thanks. Mike Peel (talk) 18:47, 15 June 2020 (UTC)
- I would not think a user category should have a Wikidata item, let alone a Wikidata Infobox. We don't give Wikidata items to users, unless they are otherwise notable. Why to user categories? Did you build the Wikidata item yourself to get interwiki links, or did someone else build it? - Jmabel ! talk 15:59, 15 June 2020 (UTC)
- I would have thought the question can not be any clearer. But then: a bot adds the wikidata info template to a hidden adminstrative category. The category happens to be my user category, that I use to organize my work and as a "business card" of sorts, when trying to beg for a accredtion to an otherwise closed event. It is unsettling not to know how this business card will look like at the moment a host of en event will read the message that I did sent. --C.Suthorn (talk) 14:32, 15 June 2020 (UTC)
- I Think it looks good and is proper, all that is missing is a self portrait. --Richard Arthur Norton (1958- ) (talk) 22:17, 18 June 2020 (UTC)
Co-operative projects
I'm thinking of organising a project for people around my village to take photographs of local buildings (specifically buildings officially listed as of architectural or historic interest) and uploading them to Commons. Clearly there will be a number of different photographers, many of whom may have limited IT skills. Does each person have to upload their own images (it might be difficult to explain to them how to do this), or is there some way I or the project can upload them en bloc, while crediting those photographers who wish to be identified? I imagine I'm not the only person to have raised a similar issue.--Ross Burgess (talk) 15:16, 18 June 2020 (UTC)
- You need a process of releasing. Though the quick response will be to say COM:OTRS, emails to that system may take months to get looked at, and your group will probably find it frustrating if the photos get deleted after upload and have to wait months for undeletion, due to bureaucracy.
- Instead, you might think about setting up a Flickr account as the 'official' group or project account with a contact email back to yourself. Files can be uploaded directly from Flickr using the upload wizard, and a bot then reviews the license (make sure a CC license is used, not PDM).
- So long as the description on Flickr names the individual photographer, and that as part of the group/project they have individually released the image, that's probably going to be sufficient. There is a certain level of COM:AGF, but as you are here an can respond to any immediate questions, it seem doubtful that anyone would want to try deleting the results from a local photodrive.
- --Fæ (talk) 15:46, 18 June 2020 (UTC)
- Another possible approach: assuming the people you are mentioning with "limited IT skills" are nonetheless literate, you could have everyone sign a single paper document authorizing you to upload on their behalf, and forward a scan of that document to OTRS. - Jmabel ! talk 16:32, 18 June 2020 (UTC)
- I think the best way would be to make all photos as a group and all works are works by the group releasing all their rights to the group. Such an agreement could be written down, but if you trust each other an oral agreement would be enough too. --GPSLeo (talk) 17:36, 18 June 2020 (UTC)
- Another possible approach: assuming the people you are mentioning with "limited IT skills" are nonetheless literate, you could have everyone sign a single paper document authorizing you to upload on their behalf, and forward a scan of that document to OTRS. - Jmabel ! talk 16:32, 18 June 2020 (UTC)
- You can also create a category for your group, such as Category:Photographs by the Groupname, and add a paragraph about the group. Fae's idea is the best but would double your work. --Richard Arthur Norton (1958- ) (talk) 20:48, 18 June 2020 (UTC)
- Importing a Flickr album to Commons en-mass is very easy, it's built-in to the standard upload wizard and sucks in all the dates, titles, descriptions and the license is neatly reviewed by a bot. For anyone used to the Flickr interface, it's probably a lot easier to organize the photo albums there, then upload them via the Wizard an album at a time (presuming slightly different Commons cats might apply to each album) here afterwards without having to do much more to the results. --Fæ (talk) 22:01, 18 June 2020 (UTC)
- There used to be a great tool for running photo scavenger hunts, which made it easy for an organiser to upload everyone's photos. I just had a look, and I can't find the tool now (I can't remember what it was called). — Sam Wilson ( Talk • Contribs ) … 22:15, 18 June 2020 (UTC)
- Importing via Flickr, creating a category, fine. Not sure what "make all photos as a group" means. But none of that seems to address the fact that in most countries (Ross hasn't said where this is), copyright cannot be transferred orally. Hence my suggestion above. Jmabel ! talk 01:03, 19 June 2020 (UTC)
Page which should be merged
Hi, the page IIITM Gwalior is created in Wikipedia style. I believe it should be merged to its category Category:IIITM Gwalior. Thanks.--Hindust@niक्या करें? बातें! 13:31, 24 June 2020 (UTC)
- @हिंदुस्थान वासी: The entire contents of the mainspace page (which is supposed to be a gallery) is already in the category page, right down to the incorrectly-formatted link. I have nominated the mainspace page for speedy deletion under COM:CSD#GA2. Brianjd (talk) 13:39, 24 June 2020 (UTC)
- Thanks @Brianjd: ! It took us 11 years to spot that page. :D --Hindust@niक्या करें? बातें! 13:44, 24 June 2020 (UTC)
upload wizard
I understand the upload comment of the upload wizard has become more useful on 7th june 2020 betweeen 15:00 and 20:00. While this is a nice feature, well known bugs are still there. For example the "you are already uploading this file" message.
Could I have known about this change?
Will the errors in the wizard ever be fixed?
--C.Suthorn (talk) 16:28, 18 June 2020 (UTC)
- Do you mean this bug (Error after "Upload more files" (already uploading the file...))? — Sam Wilson ( Talk • Contribs ) … 22:20, 18 June 2020 (UTC)
- Ja, aber das ist wirklich nur ein Beispiel dafür, wie kaputt der Zauberer ist. Dieser Fehler ist nur eine Unannehmlichkeit, lässt sich eibnfach wegklicken. Es zeigt aber, dass der Zauberer in sich fehlerhaft ist. Ich gehe davon aus, dass das ein Symptom für Memory Leaks ist, die selber viel schlimmer sind. Besonders ärgerlich sind auch die Fehlermeldungne. Kürzlich hatte ich bein einem upoad von 153 Dateien 150 mal den Fehler "Error" (<- Das ist die vollständige Widergabe der Fehlermeldung). --C.Suthorn (talk) 04:17, 19 June 2020 (UTC)
There is no user page here, but this user has created several files. 2601:643:8101:64E1:50B1:1232:12F6:85AB 16:26, 19 June 2020 (UTC)2601:643:8101:64E1:50B1:1232:12F6:85AB
- @2601:643:8101:64E1:50B1:1232:12F6:85AB: This is normal. Users pages aren't automatically created for users, and users aren't required to create them. – BMacZero (🗩) 17:28, 19 June 2020 (UTC)
- Some of our strongest contributors choose not to have user pages. - Jmabel ! talk 23:39, 19 June 2020 (UTC)
WMF rebranding
Hi folks, just a note for those who may not have seen it already - this has been doing the rounds on enwp, but I've not seen it on Commons. Feel free to remove if it's somewhere on here that I've just missed!
You're probably aware by now that the WMF are considering rebranding, and that a survey on the topic has been started, with three options presented - all of which involve renaming Wikimedia to variants on the Wikipedia brand.
In a statement made earlier today, the WMF Head of Communications, Heather Walls, announced that when community discussions began to sway toward attempting to prevent a rebrand, we failed in clearly and consistently responding that a rebrand itself was not up for debate, and that a rebrand will happen. This has already been decided by the Board.
This is obviously of particular relevance to Commons, because "Wikimedia" is literally in the project name. | Nayptatalk opened his mouth at 22:21, 18 June 2020 (UTC)
- I predict a large number of departures of longstanding contributors over what should have been a trivial matter of listening to the community. - Jmabel ! talk 01:02, 19 June 2020 (UTC)
- Ja, aber das macht nichts. In Deutschland ersetzen AfD-Anhänger die LEute, die Sportvereine oder die freiwilligen Feuerwehren verlassen. In Amerika werden dann in gleicher Weise Trump-Unterstützer die fahnenflüchtigen Wikipedia-Mitmacher ersetzen und in Little England Boris-Brexiteers. Und die schreiben dann viele schöne neue Artikel. In der kroatischen Wikipedia hat diese Übernahme ja schon vor vielen Jahren reibungslos geklappt. --C.Suthorn (talk) 04:22, 19 June 2020 (UTC)
- I'm pretty livid about this. Especially since previously (like within the last week) staff said the opposite. Earlier this week, staff claimed that the rfc took place too early, before all the options could be considered [3], and now they claim that the decision was already made prior to the rfc even taking place. Its a nice catch-22 where the RFC took place both too early and too late at the same time. And that's not even touching on the use of statistical manipulation in the surveys. Even if one doesn't care about the naming, surely everyone should be mad about the blatant bad-faith and disrespect in the "consultation" process. Bawolff (talk) 04:57, 19 June 2020 (UTC)
- Agree this is the deeply unpleasant aspect.
- While on the one hand praising volunteers, saying how valuable their time is, on the other hand the WMF is seen to be massively wasting volunteer effort. Running an effective PR campaign while pretending it's a survey and valued feedback which in practice is pointless and will be binned at a quiet moment, is hypocrisy and seriously damaging to the trust of key stakeholders. Even now, with an open about-face confession that "we are going to ignore you whatever the feedback", they are still asking volunteers to waste our time giving yet more feedback that will make no difference to the outcome.
- It's a mockery, equivalent to sticking up a poster saying "press this fake button for free money (only press if you are stupid enough to think there is free money)". --Fæ (talk) 05:15, 20 June 2020 (UTC)
- I'm pretty livid about this. Especially since previously (like within the last week) staff said the opposite. Earlier this week, staff claimed that the rfc took place too early, before all the options could be considered [3], and now they claim that the decision was already made prior to the rfc even taking place. Its a nice catch-22 where the RFC took place both too early and too late at the same time. And that's not even touching on the use of statistical manipulation in the surveys. Even if one doesn't care about the naming, surely everyone should be mad about the blatant bad-faith and disrespect in the "consultation" process. Bawolff (talk) 04:57, 19 June 2020 (UTC)
- Ja, aber das macht nichts. In Deutschland ersetzen AfD-Anhänger die LEute, die Sportvereine oder die freiwilligen Feuerwehren verlassen. In Amerika werden dann in gleicher Weise Trump-Unterstützer die fahnenflüchtigen Wikipedia-Mitmacher ersetzen und in Little England Boris-Brexiteers. Und die schreiben dann viele schöne neue Artikel. In der kroatischen Wikipedia hat diese Übernahme ja schon vor vielen Jahren reibungslos geklappt. --C.Suthorn (talk) 04:22, 19 June 2020 (UTC)
We are the most affected project as we are the only project for externals with Wikimedia in the name. It Wikimedia gets remanded we need a new name too. commons.wikipedia.org would be a very bad name. --GPSLeo (talk) 08:30, 19 June 2020 (UTC)
- Personally I don't think the Foundation's changing its name need necessarily affect Commons. As someone (I forget who, sorry) mentioned in previous discussions, Commons has a better semantic claim to the "Wikimedia" name than almost anything else: Commons is a wiki for media, and also repository of media for wikis. The name "Wikimedia Commons" could thus be parsed as "Wiki Media Commons": the common media for multiple wikis. --bjh21 (talk) 10:14, 19 June 2020 (UTC)
- If I recall correctly, the Wikimedia Foundation is not going to abandon Wikimedia name altogether; they are going to reserve it for themselves as a redirect to their new brand. So the Commons project should not think that the "Wikimedia" name will be free to usurp. 4nn1l2 (talk) 15:24, 19 June 2020 (UTC)
- Yes, the message that has been communicated for a long time now, that the Foundation is "considering rebranding" is not accurate. Apparently, the Foundation decided a long time ago that they were going to rebrand. It's not entirely clear why they are asking for the community's opinion at all. GMGtalk 14:28, 19 June 2020 (UTC)
- I'll make a strong guess from dealing with rebranding efforts at other organizations: they asked for community input because they expected it to be enthusiastic. - Jmabel ! talk 16:10, 19 June 2020 (UTC)
Structured data postcards
I see that bots are buzy with filling in the copyrigth license data from the files. For most users this is of little search relevance. Almost by definition all files in the Commons do have to have a good copyrigth license, otherwise they are deleted. I do add some 'content' structured data to files. Is it an idea to let bots scan all postcards categories and add (P31) (Q192425) to structured data?Smiley.toerist (talk) 09:50, 19 June 2020 (UTC)
- Convenience link: wikidata:Q192425 Brianjd (talk) 14:54, 19 June 2020 (UTC)
- @Smiley.toerist: Licences are not trivial. Copyright licences have important details. Some (like GFDL) have crazy rules about not including sections with certain titles. Some (like GPL and, I think, GFDL) require you to include the entire licence text. Some (like GPL, GFDL or CC BY-SA) require you to use the same licence for derivatives. Some have none of these restrictions. Many files are not copyrighted at all; that’s important too. From what I can remember, the structure data bot(s) capture all of this information. Brianjd (talk) 14:56, 19 June 2020 (UTC)
- Regarding your categories question, apparently structured data is supposed to replace categories, so it is bound to happen anyway. For the record, I think that structured data in its current form sucks. It’s not intuitive at all, whereas categories are. Brianjd (talk) 14:58, 19 June 2020 (UTC)
- Commons Categories do not have the same function. Categories are often a combination of many Wikidata properties. For example the main category Postcard is subdivided by many location categories such as 'Postcards of Antwerp'. There is no need and it is not desirable to create similar Wikidata items. Idem for the categories of 'Postcards by publisher': Publisher is a separate property. Another example: 'Trains at Groningen station'. These subcategories are created to limit the number of files and in practice most searches are either interested in the trains or the buildings, not both. In structured data, trains will go to a depicts (P180) wikidata item and the station as a location wikidata item (Groningen station). If the main subject is the station building (with no or marginal train content) then it wil be a depict wikidata item (Groningen station). This is a fundamentaly diverend way of structuring the data. It is no way a duplication of the existing Commons categories.Smiley.toerist (talk) 10:34, 20 June 2020 (UTC)
- In practice one searches the categories upwards until the category has a linked Wikidata Item. (if the wikidata item is over a Commons:category, look at the underlying Wikidata item. One who has links to Wikipedia articles). These are the Wikidata items the bots can use in Stuctured Data. As an example I have added all all structured Data I could to File:Le chalet forestier Namur.jpg.Smiley.toerist (talk) 10:48, 20 June 2020 (UTC)
ZDF documentary videos
Hi there, I am thinking about how to help people reuse the ZDF documentary clips in category:Videos by Terra X that are in use on German wikipedia, etc. To translate to multiple languages, it would be helpful to have transcripts or subtitles, which can then be translated and / or recorded as new audio. Is there a way to add transcriptions / subtitles? The original length German videos have subtitles, which it may be acceptable to use, where the German dialogue is already released as cc-by, or otherwise Google translate could speed up transcription from German. JimKillock (talk) 10:26, 20 June 2020 (UTC)
- I found that adding subtitles is per video quite easy (thanks whoever coded it all up). I will make a stab at one of the videos and see where we can go from there. JimKillock (talk) 11:39, 20 June 2020 (UTC)
- Update, for Das Straßennetz im antiken Rom I have added German and English; a file for Latin for them to work on, and someone else has done NL! JimKillock (talk) 13:19, 20 June 2020 (UTC)
- File, I can't work out how to do this without it embedding:
Das Straßennetz im antiken Rom (CC BY 4.0) - My Workflow for subtitling
- Using Google translate phone App, play video audio from computer so Google translate app can transcribe the German from the audio
- Copy and paste the German to a file, send to computer for editing
- Listen back to the German to spot any obvious errors
- Create a German subtitle file through the "Add subtitles" link on the video player
- Listen through the video to timecode the German subtitles
- Copy and paste the German timecoded file
- Use Google translate to render the German subtitle file as English
- Edit the English to seem sensible
- Use "Add subtitles" link on the video file to create English subtitle file
- Paste in the English translation
- Create files from English or German as desired for Google or manual translation — Preceding unsigned comment added by JimKillock (talk • contribs) 17:35, 20 June 2020 (UTC)
- My Workflow for subtitling
The first video has ca, de, en, es, la, nl subtitles in an afternoon! Not bad :) JimKillock (talk) 17:43, 20 June 2020 (UTC)
- OK, someone else really needs to jump in here. I cannot believe what I am reading here! Firstly, machine translation is infamous for producing nonsense in certain cases. Secondly, and perhaps more importantly, what are the copyright implications here? Brianjd (talk) 13:16, 21 June 2020 (UTC)
- On copyright, this is a very good question.
- The transcription is a simple copy and cannot be subject to a new copyright, any more than a scan or photograph (this is long established Wikimedia policy on verbatim copies).
- I am pretty sure copyright is the result of human work, not machines, so machine translation should not be able to attract copyright. There has to be a creative element or decision; this is absent when a machine processes text. As any translation is a derivative work in any case, there is even less reason for any claim. And in any case AFAIC Google have never attempted to claim any IP rights over the results of their translate facility. Of course I am open to being told otherwise and you are completely right to ask this question.
- As for the content of the translation, I am editing it, and have just about enough German to check the English makes sense and matches it. In practice I am only using some of Google's words; mostly it is just making it a lot quicker and easier to render a translation than I woul be able to otherwise. Occasionally the German is a bit harder, and Google unhelpful; and I may have made mistakes: the texts certainly need a read through. JimKillock (talk) 15:47, 21 June 2020 (UTC)
5000 Wikiportret uploads
Hello all! I would like to draw your attention to the Wikiportrait initiative. 5000 images of notable Dutch and Flemish people have been uploaded through the Wikiportret website. The photos are visible on more then 17.000 pages in the Main namespace of all Wikimedia projects. The uploads are gathered in the category Wikiportrait uploads. Please click on GLAMorous to look for the use in your favourite project outside Commons. Of course, we will continue this project, together with the Dutch Chapter.
However, I still have a dream. The Wikiportrait software is in Dutch but could be used in other languages too. If you are interested, please read this blog. Or contact me through my talk page. Kind regards, Elly (talk) 07:51, 22 June 2020 (UTC)
Join map elements in one picture
This map was cut up and pasted on a textile support. I scanned the sections individualy, hoping to digitaly paste them together again. However the panorama photomerge from Photoshop (elements 10) refuses to merge unless there is a sustantial Common area. Is there a way (or tool) to manualy join them together?



The other method is to rescan the map with several sections and move them together (with the standaard move tool). Example:


.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg#Angora_or_Ankara){kind=link}
.jpg){kind=link}
{kind=link}
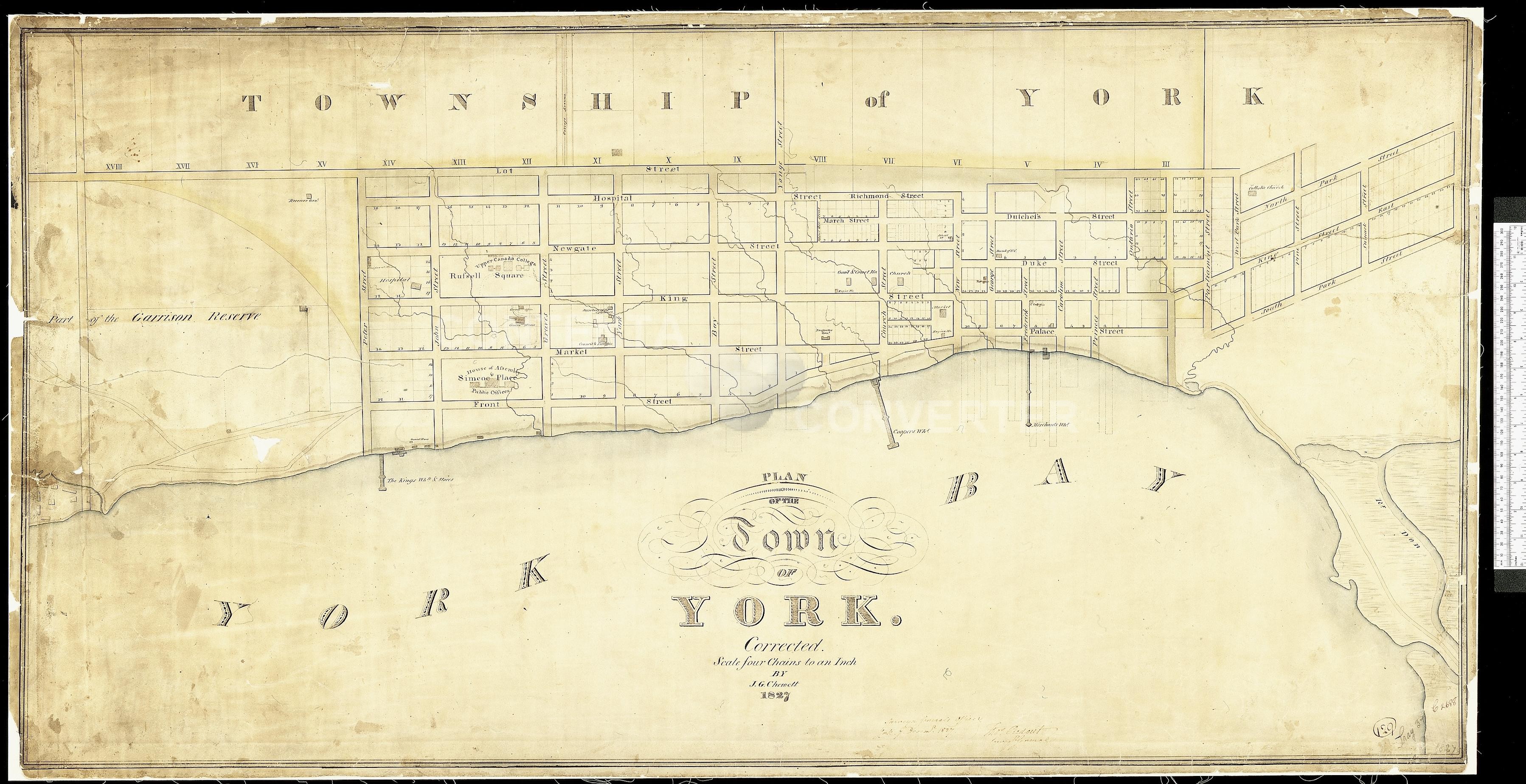{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_(49943844691).jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
.jpg){kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
.png&action=edit&redlink=1){kind=link}
{kind=link}
{kind=link}
{kind=link}
The problem is that this is limited with size of the scan area. The total map contains 3 x 7 = 21 sections. About 30 cm x 90 cm. I am only interested in the 3 selected parts. I would be nice to scan all 21 sections and digitaly recreate the original map.Smiley.toerist (talk) 11:15, 22 June 2020 (UTC)
- Smiley.toerist, I would suggest taking this to Commons:Graphic Lab/Map workshop and letting those folks take a look. — Huntster (t @ c) 12:48, 22 June 2020 (UTC)
Commons partnerships emails
Hi All,
I've created a new page, Commons:Example requests for partnerships which contains sample emails that can be sent to potential GLAM partners. I hope it makes it easier to contact institutions, feel free to expand/edit.
Best, --Adam Harangozó (talk) 11:42, 22 June 2020 (UTC)
- I can’t believe we don’t already have such a page. @ShakespeareFan00 had the excellent idea of writing to GLAMs asking them to mirror (public domain) material on Commons as well as the Internet Archive. That letter should be added to this collection. Brianjd (talk) 11:48, 22 June 2020 (UTC)
Importing maps from Open Street Maps
Hi!
I'd like to import a map that depicts an avenue, in order to illustrate an article in the Portuguese WP about said avenue (as done previously in File:OSM-Lisboa-AvenidaLiberdade.jpg).
{kind=link}
What's the best way to do this? I've been searching in both Commons and OSM and can't find a tutorial concerning this... Thanks in advance! JonJon86 (talk) 10:39, 15 June 2020 (UTC)
- @JonJon86: I think you can just take a screenshot and upload it here, making sure to add the appropriate tags (see Commons:Village pump/Copyright#Are screenshots of openstreetmap free to upload?). Or, even better, it should be possible to embed an interactive map into the article. I’ve seen this but I don’t know how to do it myself. Brianjd (talk) 13:42, 15 June 2020 (UTC)
- Hi @JonJon86: , please join the OpenStreeMap slack where there is a Wikimedia channel :) https://slack.openstreetmap.us/ Sorry I can't be of more direct help! Carlinmack (talk) 22:53, 22 June 2020 (UTC)
- The main OpenStreetMap domain is openstreetmap.org. I am sure that the openstreetmap.us people are nice and do good things, but I don’t know whether this domain is official. (If you did not know about the .org domain, you would probably think the .us domain is official. This is a worry.) Brianjd (talk) 10:16, 23 June 2020 (UTC)
- Use wget to get the map. but BUT NOTE THE CPOYRIGHT PROBLEMS IF YOU POST IT — Preceding unsigned comment added by ThesenatorO5-2 (talk • contribs) 06:17, 30 June 2020 (UTC)
{kind=link}
Closed by me (non-admin). Re-opened by E4024 (non-admin). Closed by Mdaniels5757 (non-admin), then self-reverted. This is getting ridiculous. Could someone take a look at it?
This also exposes a more general problem with re-opening DRs (basically, no one knows how to do it correctly):
- Neither user restored the DR tag on the file description or removed {{Kept}} on the talk page (I fixed both of these issues).
- By the time E4024 re-opened the DR, Krdbot had already removed it from the daily DR list, making it difficult to find. I have not restored it. Instead, I asked E4024 to comment on it, but they failed to do so. Later, I mentioned it on User talk:Mdaniels5757, but they also failed to respond. Is there any standard way of dealing with this? (By “this” I mean the daily DR list issue; I do not want this to escalate into a dispute about other users.)
Brianjd (talk) 15:24, 25 June 2020 (UTC)
{kind=link}
- I was actually just about to respond to you on my talk (just opened my computer for the day :) ); I have now done so. I think the best way to fix the daily DR list issue is probably to re-transclude on the daily log and un-transclude on the archive page. I've done so for this discussion. I'd have to remember to do so in the future, but that's a separate issue... --Mdaniels5757 (talk) 15:33, 25 June 2020 (UTC)
- @Mdaniels5757: That’s understandable. :) But given the history of this DR, and the fact I’ve already posted here, I think it’s time to have a wider discussion about this. Brianjd (talk) 15:37, 25 June 2020 (UTC)
I have an edit in my edit history I do not remember making
Hello, today I have received a notification about an edit of mine being reverted, and I do not remembeer making this edit. The edit in question is this, I can see that theoretically it could be a copy-paste error, but I am a bit weirded out by that. I am going to change the password right now, but is there a way to easily get edits immediately before and immediately after this one? ℺ Gone Postal (〠 ✉ • ✍ ⏿) 13:50, 26 June 2020 (UTC)
We have just had a discussion about this file, which has just been archived at Commons:Village pump/Archive/2020/06#Potential huge mess, how to deal with it?. I would like to revive this discussion. It only went idle because @Cush was waiting for a response from @MissMJ. You might be waiting a while, because @MissMJ’s last contribution was in 2013. Pinging @Speravir, King of Hearts, AnonMoos.
I happened to come across this file at Commons:Help desk#Copyright violation on external site, and commented there about how confusing it was; then I remembered this discussion. Brianjd (talk) 10:10, 23 June 2020 (UTC)
{kind=link}
- @Brianjd: If you feel a discussion wasn't completed, you can unarchive it and bring it back to this page. - Jmabel ! talk 14:49, 23 June 2020 (UTC)
- I had this in mind all the time. Unfortunately I had not noticed that Cush hat added an answer below my long reaction …
 . — Speravir – 01:23, 24 June 2020 (UTC)
. — Speravir – 01:23, 24 June 2020 (UTC)
- For a split request see COM:SPLIT (actually a bit lower). — Speravir – 01:36, 24 June 2020 (UTC)
- Stop attacking me. Cush (talk) 08:17, 24 June 2020 (UTC)
- What? Actually I tried to respond to your latest answer in the now archived thread, so this new reaction is quite odd. I requested the split now for you. — Speravir – 22:00, 24 June 2020 (UTC)
- Stop attacking me. Cush (talk) 08:17, 24 June 2020 (UTC)
- For a split request see COM:SPLIT (actually a bit lower). — Speravir – 01:36, 24 June 2020 (UTC)
Books from Great Britain
Currently there is a series of categories Books from Great Britain by year spanning from 1425 to 1934. There is also Books from the United Kingdom by year spanning from 1733 to 2001. Is Category:Books from Great Britain by year supposed to be scoped to the Kingdom of Great Britain (in which case it should span from 1707 to 1801) or to the island of Great Britain (in which case it should span from the Middle Ages to today)? There seems to be no consistency in how the categories are used. British books from the 1800s are sometimes in one category and sometimes in the other and sometimes in both, making the categories somewhat useless for actually finding what you're looking for. Kaldari (talk) 19:31, 24 June 2020 (UTC)
- Yes I've had problems with this, I would like to merge the Great Britain category into the United Kingdom category, but I'm not knowledgeable about the difference, or if it matters. I opened Commons:Categories for discussion/2020/06/Category:Books from the United Kingdom by year for any suggestions and if it is an acceptable move I'll go ahead and do the merge. Thanks for any comments Ruff tuff cream puff (talk) 00:22, 25 June 2020 (UTC)
Mirroring works from "Internet Archive"
There was a proposal to mirror certain resources from IA to Commons: Commons:Village_pump/Proposals#Mass_"Evacuation"_copy_of_Public_domain_resources_from_Internet_Archive_to_Commons.
It's starting to happen! - User talk:Fæ/CCE volumes#Forks.
What's needed from Commons contributors and admins
- Checking items in the categories linked from User talk:Fæ/CCE volumes , to ensure they are correctly licensed.
- Checking the meta-data swept from IA, against additional ndications in the scanned works themseleves.
- Identification (and rapid removal) of material which is not license compatible with Commons, or which would still be in Copyright.
- Conversion of the Userspace page, into a more formal WikiProject page in consultation with User:Fæ
amongst many other enumerable tasks.
One contributor cannot curate this content alone. It needs many.
Let's keep the 'Public domain' free, accessible and presented with an appropriate context!
Pinging: @Fæ, Nemo bis, MGA73, Koavf, and Brianjd:
ShakespeareFan00 (talk) 20:48, 24 June 2020 (UTC)
- Very happy to help. If you want to make a list of all uploads and break them into tranches of 100 or something, you can assign me a batch to look over. Let me know. —Justin (koavf)❤T☮C☺M☯ 20:52, 24 June 2020 (UTC)
- I think User:Fæ has a list, The page linked above has a section for the Forks of the original script User_talk:Fæ/CCE_volumes#Forks which has links to the categories which contain what's been uploaded so far. The categories can be group into batches of 200 IIRC. An alternative is to use the Upload log. https://commons.wikimedia.org/w/index.php?title=Special:Log&offset=20200624173809&limit=100&type=upload&user=F%C3%A6&page=&wpdate=&tagfilter=&subtype= the earliest entry I can find relating to the additional forks is on https://commons.wikimedia.org/w/index.php?title=Special:Log&dir=prev&offset=20200610115153&limit=100&type=upload&user=F%C3%A6&page=&wpdate=2020-06-04&tagfilter=&subtype=
(Dated 14:59, 12 June 2020). Most of the earlier items uploaded in this effort are in distinct "collections" and thus potentially fairly easy to review at rapid pace. ShakespeareFan00 (talk) 21:03, 24 June 2020 (UTC)
- @Fæ and ShakespeareFan00: If one of you (naturally, it should be Fae) are willing to take ownership over this list, divide it into manageable sections, and assign me some, I will check them and mark them off the list. —Justin (koavf)❤T☮C☺M☯ 21:17, 24 June 2020 (UTC)
- Paging @AntiCompositeNumber: , Is some way of generating a 'batched' list of the uploads for review, from the log feasible (perhaps using the API backend)? Given the volumes involved splitting it by hand would be too cumbersome I feel. ShakespeareFan00 (talk) 21:26, 24 June 2020 (UTC)
- The easiest way of doing it would be to create a backlog 'to review' category, targeting the collections for which there might be some doubt but avoiding the obvious (like anything dating before 1870).
- Then batching could be done using a search either by year ranges or by taking alphabetic chunks of internet archive identity numbers (which are the default sort for the categories) and volunteers removing the backlog category as they go along, which is super quick.
- It would help for folks to raise exemplar deletion requests where there is significant doubt in a particular scenario (like documents dated 1920 published in Mexico).
- Completed are the seed catalogues and census bureau, though both collections are probably all uncontroversial. I'll add some 'done' marks tomorrow to make it clearer what's done. --Fæ (talk) 21:57, 24 June 2020 (UTC)
- Paging @AntiCompositeNumber: , Is some way of generating a 'batched' list of the uploads for review, from the log feasible (perhaps using the API backend)? Given the volumes involved splitting it by hand would be too cumbersome I feel. ShakespeareFan00 (talk) 21:26, 24 June 2020 (UTC)
@Fæ, Koavf, and Billinghurst: : Some of my recent edits Special:Contributions/ShakespeareFan00 have been to add links to Creator: for works, or to suggest renamings. I can continue if this is thought to be worthwhile, However, I'm not an expert when it comes to tracking down author details from more obscure bibliographic sources, Hence why I've pinged a respected contributor I know has more expertise in this area. ShakespeareFan00 (talk) 11:12, 25 June 2020 (UTC)
License burried deep inside archived page's source code
I need some help here: Commons:Deletion requests/File:Zoey Deutch at Golden Globes Red Carpet 2020.png. Gikü (talk) 07:38, 25 June 2020 (UTC)
{kind=link}
media-list API
The media-list API returns all images found in a page. For instance https://de.wikipedia.org/api/rest_v1/page/media-list/Wikipedia%3AHauptseite%2FSchon_gewusst%2FZeittafel returns all images on that Wikipedia page.
How to get all images on a user page? Strangely https://commons.wikimedia.org/api/rest_v1/page/media-list/User%3ASyced does not work.
Is my syntax wrong? Or maybe Commons does not have the media-list API? Thanks! Syced (talk) 15:30, 25 June 2020 (UTC)
Marah oreganus/oregana
Category:Marah oregana currently gives a message:
Error in Wikidata: wikidata cat item 'Category:Marah oreganus' (Q55299916) property 'Commons category' (P373) should be 'Marah oregana' (not Marah oreganus). Error in Wikidata: wikidata gallery item 'Marah oreganus' (Q3845272) property 'Commons category' (P373) should be 'Marah oregana' (not Marah oreganus).
I have no real idea whether the error is in Commons' naming or Wikidata's; I do know that en-wiki calls this Marah oreganus, and the only other two wikipedias with articles on this (Italian and Vietnamese) agree with en-wiki, but they are likely to have derived from en-wiki.
I'm not nearly strong enough in botany or taxonomy to have an independent opinion here, but clearly either Commons or Wikidata is wrong. Also: why do we write our error message in a way that presumes Wikidata is wrong and Commons is right? - Jmabel ! talk 07:50, 29 June 2020 (UTC)
- User:MILEPRI: you seem to have been the one who moved the commons category from Category:Marah oreganus to Category:Marah oregana. What was this based on? - Jmabel ! talk 07:52, 29 June 2020 (UTC)
- Marah oregana es el taxón aceptado por: Catalogue of Life,IPNI, Kewscience, Tropicos. Todas estas referencias las puede consultar en Wikispecies. Esperando haberlo aclarado, le saluda.--MILEPRI (talk) 08:28, 29 June 2020 (UTC)
- Grácias. (¡No conocí que sea hispanohablante!) Parece que los demás deberían cambiar, no Commons. - Jmabel ! talk 15:26, 29 June 2020 (UTC)
- Marah oregana es el taxón aceptado por: Catalogue of Life,IPNI, Kewscience, Tropicos. Todas estas referencias las puede consultar en Wikispecies. Esperando haberlo aclarado, le saluda.--MILEPRI (talk) 08:28, 29 June 2020 (UTC)
- @Jmabel: The actual error message was because in the Wikidata item at one place there was still
Category:Marah oreganusto be found, . For reasons I will never really understand there are two possible places for adding a Commons category. On moving apparently only one is adjusted. For the scientific name the question is, whether Marah is grammatically masculine (→ oreganus) or feminine (→ oregana). — Speravir – 18:11, 30 June 2020 (UTC)- But the category is not updated … — Speravir – 18:19, 30 June 2020 (UTC)
- … because I updated only one of the items causing the error. — Speravir – 21:35, 30 June 2020 (UTC)
- But the category is not updated … — Speravir – 18:19, 30 June 2020 (UTC)
- This section was archived on a request by: Speravir 16:17, 1 July 2020 (UTC)
Do we have a guide on how to provide OTRS permission?
I found a series of photos related to a historical event made by an onlooker that I want to add to Wikipedia collection. I established communication with the son of that photographer (who is deceased by now) who is willing to PD these photographs. Can you please outline the steps for him to do so in a manner that would be recognized by Commons? Thank you. -- Wesha (talk) 13:23, 21 June 2020 (UTC)
- @Wesha: Please see COM:OTRS/CONSENT. --Wcam (talk) 15:37, 21 June 2020 (UTC)
- @Wesha: But also: often much simpler that the OTRS process is to make the license clear at the original site where things are posted, as long as that is clearly under the control of the copyright-holder. Then cite that site that as source. Much quicker and easier. - Jmabel ! talk 15:46, 21 June 2020 (UTC)
- @Jmabel: I think you mean “cite”. :) And that is a good idea, assuming the copyright owner actually has their own site. Brianjd (talk) 15:50, 21 June 2020 (UTC)
- @Brianjd: Actually, I meant "cite that site", but I just woke up. - Jmabel ! talk 16:01, 21 June 2020 (UTC)
- The content owner doesn't "have their own site", they are posting on a public forum where enthusiasts are talking about old photos. I am not sure that is sufficient for OTRS. -- Wesha (talk) 18:47, 21 June 2020 (UTC)
- If the son of the original photographer is willing to PD his inherited images, it is a case for COM:CONSENT. And yes, posting the images in a user-generated public forum isn't helpful. If they have been posted before though, he should mention the weblinks in his OTRS email. De728631 (talk) 19:03, 21 June 2020 (UTC)
- Actually, if the photos were first published in a user-generated content site, a public license declaration there is more helpful than OTRS since social media profiles often do not list email addresses. However, in this case he gave his email publicly in the thread so either OTRS or public declaration will work. -- King of ♥ ♦ ♣ ♠ 16:12, 25 June 2020 (UTC)
- If the son of the original photographer is willing to PD his inherited images, it is a case for COM:CONSENT. And yes, posting the images in a user-generated public forum isn't helpful. If they have been posted before though, he should mention the weblinks in his OTRS email. De728631 (talk) 19:03, 21 June 2020 (UTC)
- @Jmabel: I think you mean “cite”. :) And that is a good idea, assuming the copyright owner actually has their own site. Brianjd (talk) 15:50, 21 June 2020 (UTC)
- Provided, of course, that the son alone holds the inherited rights to the material. --Pitke (talk) 11:57, 26 June 2020 (UTC)
A full set from 1891 to 1978. I think these are the source for checking a pre 1978 work for copyright status in the US? 88.97.96.89 23:27, 26 June 2020 (UTC)
x year paintings in country y
Hi. I have just spotted that File:Stuart, Gilbert - Henrietta Elizabeth Frederica Vane - 1783.jpg has the category Category:1783 paintings in the United States. Does this category mean that it is a "painting made in the USA in 1783" or that it is a "painting made somewhere in 1783 that currently resides in the USA"? I notice that we have some other categories that use "from" to determine the origin. The reason I would like to clarify the situation in this case is that the artist, en:Gilbert Stuart wasn't in the USA between 1775 and 1793. If it is meant to indicate country of origin, I will remove the category. From Hill To Shore (talk) 23:59, 27 June 2020 (UTC)
{kind=link}
- Typically, a category like that would mean "currently resides in the USA". But, in general, while it would be a massive project, we would do well to also have "country of origin by year" categories for artworks. - Jmabel ! talk 02:13, 28 June 2020 (UTC)
ZDF German subs need checking, content needs promoting
Hi there, as mentioned previously I have been adding German subtitles to the 58 high quality ZDF documentary clips. About two thirds now have subtitles, the remainder I am unlikely to subtitle. A few points:
- My subtitles are auto transcribed and roughly checked by me. There are errors!
- They need a native / high functioning German speaker to check them through! Some have been check but all should be rechecked
- Find the subtitled files at category:Videos by Terra X with German subtitle file
- The time stamps are mine alone, they should be mostly fine. — Preceding unsigned comment added by JimKillock (talk • contribs) 09:37, 28 June 2020 (UTC)
- Checking isn't a difficult job, so please do if you have the ability
- German subs are the first step to further usage, beyond German speakers. Once subs are available, other langauge users can
- Translate the subs relatively easily, without the pain of doing the timestamps
- Consider redubbing the content, adapting any translation as they like
As this is really good content I think multilingual subs and / or redubbing is well worthwhile. I am not well connected within the Wikipedia community though so someone else will need to think about how to do the promotion. If anyone wants to do this or has advice about how to do this please let me know. JimKillock (talk) 09:31, 28 June 2020 (UTC)
- @JimKillock: Thanks a lot for that! I've checked all remaining German subtitles. All done now. --Jcornelius (talk) 19:42, 28 June 2020 (UTC)
- @Jcornelius: Thank you! That's great – next I will work on some English subtitle files, much as the German this will need checking, but it will be a while before these are ready. JimKillock (talk) 19:54, 28 June 2020 (UTC)
MediaWiki:Licenses
Please could someone with the necessary rights attend to the changes discussed in MediaWiki talk:Licenses? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 11:05, 28 June 2020 (UTC)
Retroactively adding a category for a GLAM
We now have literally thousands of pictures from the Seattle Municipal Archives, but we never set up a category for them as a GLAM. I'd like to remedy that; if we set up such a category, is there an easy way to add the category to all images with https://www.flickr.com/photos/seattlemunicipalarchives as part of their file-page wikitext? That will be at least the bulk of such images; it will certainly be less daunting to find the outliers by hand than to go through finding all of these. - Jmabel ! talk 23:30, 23 June 2020 (UTC)
- @Jmabel: I used the search "insource:https://www.flickr.com/photos/seattlemunicipalarchives" and User:BMacZero/gallery.js to generate User:BMacZero/Search results (1539 files). Looks like you can run VFC on that gallery to add the category, or let me know if you want me to tackle it. – BMacZero (🗩) 23:50, 23 June 2020 (UTC)
- Actually, you can also run VFC directly on the search results page. – BMacZero (🗩) 23:53, 23 June 2020 (UTC)
- @BMacZero: Thanks! I can take it from there. - Jmabel ! talk 23:55, 23 June 2020 (UTC)
- No, I guess I can't take it from here. Using regular expressions, I don't see how to reuse a matched string in the replacement, and it looks like there is no relevant example in Help:VisualFileChange.js/samples. Basically I want to match the following regex; this is PHP style, not sure how that compares to what VFC may need:
- /[|]\s*[Ss]ources\s*=[^|}]*/
- Then if we call the matching string %0 (but in fact I have no idea how to refer to it in VFC), I want to replace that by:
- %0\n{{Seattle Municipal Archives via Flickr}}
- Other than the %0 and the \n (newline), that last is a literal string.
- Because regexes can be a bit of a "write-only language", let me paraphrase my intent for the match:
- A single pipe character (and, yes, you can also write that as '\|')…
- any amount of whitespace…
- "Sources", initial letter may or may not be capitalized…
- any amount of whitespace…
- a single equality character…
- a string consisting of anything but a pipe character or closing curly bracket, which should bring us to the end of the source field; the next pipe character would be the beginning of the next field; allowing also for the template ending here (no next field).
- Can anyone help me out? And can someone document how you use a regex here if you care to reuse the value the regex matches? - Jmabel ! talk 03:56, 24 June 2020 (UTC)
- @Jmabel: That's pretty close. If you want to grab part of the matched string for use in the result, you have to wrap it in parenthesis ().
/([|]\s*[Ss]ource\s*=[^|}]*)/. And you reference the match with $1 in whatever flavor this is (yes, it's one-based for some reason, I don't know why). – BMacZero (🗩) 04:27, 24 June 2020 (UTC) - Ah, '$' instead of '%'. And probably 1 is first parenthesized expression, 0 is the whole string.
- Is the $1 thing documented somewhere, or was this done by a PERLer who just thought that was common sense? - Jmabel ! talk 04:46, 24 June 2020 (UTC)
- It's not super well documented, but it's mentioned in the dropdown that enables it (Preserve nowikis, comments. Allow usage of substring and $1 (internal usage of placeholders (%v%f%c%\d+)).). The $ syntax comes from the ECMAScript RegExp standard, which was modeled after but is not exactly the same as the PCRE syntax. AntiCompositeNumber (talk) 05:18, 24 June 2020 (UTC)
- We probably should add an example of this in the examples for using VFC. Does someone else want to do that, or should I? - Jmabel ! talk 17:26, 24 June 2020 (UTC)
- Having gotten no further response, I'll take that on. - Jmabel ! talk 00:08, 30 June 2020 (UTC)
- We probably should add an example of this in the examples for using VFC. Does someone else want to do that, or should I? - Jmabel ! talk 17:26, 24 June 2020 (UTC)
- It's not super well documented, but it's mentioned in the dropdown that enables it (Preserve nowikis, comments. Allow usage of substring and $1 (internal usage of placeholders (%v%f%c%\d+)).). The $ syntax comes from the ECMAScript RegExp standard, which was modeled after but is not exactly the same as the PCRE syntax. AntiCompositeNumber (talk) 05:18, 24 June 2020 (UTC)
- @Jmabel: That's pretty close. If you want to grab part of the matched string for use in the result, you have to wrap it in parenthesis ().
Blazonry
If you are into shields/blazons/coats-of-arms, and maybe know a code/language called blazonry, you might enjoy my new tool to generate them. --Magnus Manske (talk) 15:22, 24 June 2020 (UTC)
- Examples. --Magnus Manske (talk) 15:22, 24 June 2020 (UTC)
- this is cool! thx!--RZuo (talk) 19:16, 29 June 2020 (UTC)
Taiwan railways

This is not Hsinchu station but a HSL station to the south of Miaoli. I got confused because I later took a train at Hsinchu station, but took no pictures. Does anyone know wich station?Smiley.toerist (talk) 12:10, 26 June 2020 (UTC)
- I think it is the THSR Chiayi Station.Smiley.toerist (talk) 19:41, 27 June 2020 (UTC)
- Solved, rename started.Smiley.toerist (talk) 17:57, 29 June 2020 (UTC)
Mass adding categories
Suppose I have a list of file names, such as that at the foot of File:Biologia Centrali-Americana (8271463253).jpg. What tool will let me add all of the listed files to a specified category? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 14:03, 29 June 2020 (UTC)
.jpg){kind=link}
- @Pigsonthewing: I don't know of one for a general list, but for that particular list you could use Cat-a-lot on Special:Search/linksto:"File:Biologia Centrali-Americana (8271463253).jpg". --bjh21 (talk) 15:18, 29 June 2020 (UTC)
- A bit roundabout, but you could also copy the list into a gallery on a sandbox page and run VFC on that page. – BMacZero (🗩) 16:29, 29 June 2020 (UTC)
.jpg%22){kind=link}
Both clever solutions; thank you. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 18:05, 29 June 2020 (UTC)
- also COM:AWB.--RZuo (talk) 19:16, 29 June 2020 (UTC)
The state of the help pages ..
.. leaves much to be improved.
I was trying to find out what information should generally be entered in the "caption" box versus the "description" field of an image (when I come across images which haven't been proberly labelled) and performed a search of the help pages using these terms:
- description versus caption
- description caption box
- description caption field
There were no relevant results ...
Browsing the help pages for information on this topic I came across some ambiguities on Commons:First_steps/Quality_and_description which I mention on the talk page.
Doing this I noticed that the questions posed on this talk page have not received any answers since around 2010.
This obviously leads to the question of whether the foundation shouldn't perhaps focus on fixing some of the basics of the apparatus before initiating a comparatively insubstantial rebranding process.
The file and category cleanup that constantly needs to happen is already a strain for the community of volunteers and maybe some extra ressources would be required to sufficiently deal with the fundamental deficiencies of the help pages.
After all thousands of images are uploaded every day and most of the occasional users must be facing the same issues and must be confused when trying to find relevant information in the help pages.
Shouldn't there be a more "institutionalised" way of establishing a coherent system of help pages which comprises a routine review of the relevant talk pages and the help desk and using this information to update and generally improve the catalogue of help pages of this central repository of the universe of Wiki... ?
(.. not to mention the state of the help pages of the German and probably many other Wikipedias ..)
best regards,
KaiKemmann (talk) 10:04, 19 June 2020 (UTC)
- One solution is to use Google search. This gives commons:File_captions. Wouter (talk) 14:58, 19 June 2020 (UTC)
- If you’re telling people to use an external search engine, instead of your own search engine, to find documentation on your own site, then you have a bigger problem.
- That page says that captions are under CC0. Wait, what? The system didn’t bother to point that out when I went to edit some captions. (Doesn’t bother me, since I put everything under CC0 anyway, but I really think this needs to be changed.) Brianjd (talk) 15:03, 19 June 2020 (UTC)
- I believe you will have a hard time here finding anyone enthusiastic about captions. They were more or less imposed on Commons by the Wikidata team. - Jmabel ! talk 16:13, 19 June 2020 (UTC)
- Captions are pointless, a vandal magnet, and confuse newbies by forcing them to enter some vague text in that box before they even get to the real description box where they then realize they have to type in the same thing again. If everyone were not so tired trying to adapt to pandemic fallout and spending our nights worrying about the multiple existential threats, we might have run a RFC to get the upload wizard and image page layout changed back by now. Oh, yes, making them CC0 was never properly agreed with the Commons community when everything we have ever typed here is CC-BY-SA and cannot be "undone" to pretend it's now CC0 and can be cut and paste into a CC0 compliant free database for Google to harvest for a commercial AI service. --Fæ (talk) 05:58, 20 June 2020 (UTC)
- Actually, what I meant was that the software needs to be changed to make it clear to users that structured data is CC0 (I think it applies to all structured data, not just captions). About changing the policy to not use CC0 at all, it’s a nice idea but it’s too late for that now, isn’t it? Brianjd (talk) 08:37, 23 June 2020 (UTC)
- Just chiming in to join the chorus that captions are bad. Between annotations, captions, categories, the description template, and structured data statements, we have a very confusing, very cumbersome, and very broken system to essentially have five different things doing roughly the same thing and they have different licenses and with a clunky interface that is outright hostile to users in my estimation. The roll out of structured data here is sincerely the biggest blunder I have seen in 17 years using WMF wikis. I'm not one for mindlessly whining about the WMF and I really don't see why others do so but man, this was 100% forced onto this project with no real forethought and it is a sorely broken system. —Justin (koavf)❤T☮C☺M☯ 08:17, 20 June 2020 (UTC)
- I’ve commented elsewhere how strongly opposed I am to structured data. It sounds like a nice idea, but they way it has been implemented, it is virtually impossible for ordinary people to use properly. Brianjd (talk) 08:37, 23 June 2020 (UTC)
Thank you for your comments.
I now understand the relation of "caption" and "description" to be a contentious point. And apparently what we see now maybe not to be the final stage of the development?
For the meantime maybe the fields "caption" and "description" could be renamed or annotated in order to make the difference and effects of each a little clearer. For example:
- "caption - may contain up to 50 words - will appear as the title of the corresponding Wikidata entry - will appear prominently on the file description page"
- "more detailed description - may contain up to 2000 words - will not appear in the Wikidata entry - will appear ..."
(I have no idea if any of this is correct .. just trying to figure out how the status quo could be improved for ignorant users such as myself ..)
thanks again,
KaiKemmann (talk) 20:14, 30 June 2020 (UTC)
Making Hot Cat easier to use
I made this request at MediaWiki talk:Gadget-HotCat.js a couple of weeks ago, but it seems no-one is looking in there.
At the moment when one clicks on hot cat for a category, it opens a drop-down box with five choices, and a scroll bar to make other choices accessible. Given that many categories have 100 or more subcategories to chose from, this makes finding others by scrolling very difficult: a tiny touch of the scroll button and suddenly you're 20 subcategories lower or higher, and missed the others inbetween.
Suggestion: please make Hot Cat tall enough to show 50 choices at a go from the drop-down, not just 5.
Could this see some action, please? Thanks! - MPF (talk) 00:41, 28 June 2020 (UTC)
- I would not support this as a default option. I have enough problems with that select box getting in the way as it is. --AntiCompositeNumber (talk) 01:20, 28 June 2020 (UTC)
- I am against a change, too, especially for such a huge dropdown list. I answered this on the gadget talk page, but let me phrase it here, as well: Use the dedicated user setting, either
JSconfig.keys['HotCatListSize']orwindow.hotcat_list_sizein your common.js or systemwide in your global.js, cf. Help:Gadget-HotCat. Additionally, you could even remove the arrow button, because if you enter a letter the dropdown is opened anyway; this isJSconfig.keys['HotCatUseCategoryLinks']orwindow.hotcat_use_category_linksset to false. (I myself use thewindowvariants and can tell you that they work). — Speravir – 03:27, 28 June 2020 (UTC) - i think this is a good idea, but maybe limit it to 10 instead of 50.--RZuo (talk) 19:16, 29 June 2020 (UTC)
- Thanks! I didn't know there was any option to set the number; perhaps this option needs to be more prominently advertised in the Hot Cat info? While I'd prefer to be able to set to 50 lines, the 30 maximum currently allowed certainly helps a lot. - MPF (talk) 21:42, 30 June 2020 (UTC)
If I could have a preview of a category when my cursor hovers over it
i am diffusing some categories of persons, but i cant really remember who's who. right now i am clicking into each to see. if commons could have something similar to "Page previews" on wikipedia, such that i can hover over a cat and see the image set to image (P18) or a random one if P18 is not set, it would save so much work!--RZuo (talk) 19:16, 29 June 2020 (UTC)
- en:Wikipedia:Tools/Navigation popups - avilable on this project, as a gadget - does that. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 19:26, 30 June 2020 (UTC)
Is Commons' aim to store all free scientific articles?
There're several million scientific articles in free license. Is every such article in scope of Commons?--GZWDer (talk) 12:51, 17 June 2020 (UTC)
- Let’s discuss this! In the DR you referenced, an admin (@Mys 721tx) says “no”. But in Commons:Village pump/Archive/2020/05#Commons:Deletion requests/File:Viruses in Humans and Animals.pdf, another admin (@King of Hearts) says “yes” (provided they are peer-reviewed):
- Actually, "peer-reviewed academic papers" are explicitly permitted per COM:SCOPE.
- For the DR you referenced, this is a moot point, as the file is in use. I have mentioned this at the DR as well. Brianjd (talk) 13:39, 17 June 2020 (UTC)
- "A PDF or DjVu file of a published and peer-reviewed work would be in scope on Wikisource and is therefore also in scope on Commons." An entry on Wikidata does not constituted in-use on Wikisource. -Mys_721tx (talk) 18:29, 17 June 2020 (UTC)
- However, in-use on Wikidata constitutes as in scope for Commons, as being used on another Wikimedia project. --Jonatan Svensson Glad (talk) 18:54, 17 June 2020 (UTC)
- The text you quoted does not say “in use on Wikisource”. It says “in scope on Wikisource”. Which the file subject to this nomination is, as far as I can tell (but I am unfamiliar with Wikisource). This is separate to it being in use on Wikidata. Brianjd (talk) 02:32, 18 June 2020 (UTC)
- I agree that the file is in-use. However, Hans Publishers is possibly predatory. The quality of the review is questionable. Articles in open access predatory journals have the guise of peer-review and a compatible license yet they have little education value. The policy needs to be updated to exclude those. -Mys_721tx (talk) 03:10, 18 June 2020 (UTC)
- Is preadatoryjournals.com itself reputable? The best external source I could find is [4] (via enwiki), which recommends researchers check one of the sites listed there (including predatoryjournals.com).
- Perhaps we should look at predatoryjournals.com itself. It does not seem to give any details on why Hans Publishers is listed as predatory. The article in question is from a journal called “Dynamical Systems and Control”, which is not listed on predatoryjournals.com.
- I suppose we’ll need to clarify this if we’re going to update the policy. Brianjd (talk) 03:49, 18 June 2020 (UTC)
- I should point out that Hans Publishers is also on Beall’s List, again with no apparent explanation. Brianjd (talk) 03:53, 18 June 2020 (UTC)
- preadatoryjournals.com states that they inherited the list from Beall. The journals on Beall's list are standalone such that those journals do not have a publisher. A journal published by a publisher would not be included in the standalone list. Perhaps DOAJ could be used as what journals is allowed. -Mys_721tx (talk) 22:20, 18 June 2020 (UTC)
- I think these big text files should not be added, unless there is an Wikisource entry. Better to sourcelink the PDF by the Wikipedia articles, with the advantage of keeping up with updates. Wikisource can only have public domain entries. Because of that most Wikisource entries are historical text and literature.Smiley.toerist (talk) 16:17, 22 June 2020 (UTC)
- @Smiley.toerist: I can’t work out what you’re trying to say. If a paper is public domain, then put it on Wikisource and it’s fine. If a paper is copyrighted but freely licensed, then it’s not worth hosting. Did I get that right? We have plenty of externally-published files, and there is no precedent for this “sourcelink to save space and keep up with updates” thing, as far as I know. If it’s in scope, we should have a copy. (Otherwise, we might be scrambling to make a copy later.) Brianjd (talk) 10:35, 23 June 2020 (UTC)
- @Brianjd Let me know your though on using DOAJ as a list of permitted open access journals. Also should thre be a new thread to discuss how to update COM:SCOPE? -Mys_721tx (talk) 08:09, 26 June 2020 (UTC)
- @Smiley.toerist: I can’t work out what you’re trying to say. If a paper is public domain, then put it on Wikisource and it’s fine. If a paper is copyrighted but freely licensed, then it’s not worth hosting. Did I get that right? We have plenty of externally-published files, and there is no precedent for this “sourcelink to save space and keep up with updates” thing, as far as I know. If it’s in scope, we should have a copy. (Otherwise, we might be scrambling to make a copy later.) Brianjd (talk) 10:35, 23 June 2020 (UTC)
- I agree that the file is in-use. However, Hans Publishers is possibly predatory. The quality of the review is questionable. Articles in open access predatory journals have the guise of peer-review and a compatible license yet they have little education value. The policy needs to be updated to exclude those. -Mys_721tx (talk) 03:10, 18 June 2020 (UTC)
- "A PDF or DjVu file of a published and peer-reviewed work would be in scope on Wikisource and is therefore also in scope on Commons." An entry on Wikidata does not constituted in-use on Wikisource. -Mys_721tx (talk) 18:29, 17 June 2020 (UTC)
- There are millions of PD books are they all in scope - Yes. Is someone going to import them all - Unlikely. Same with photographs (useful for educational purposes) or with photographs of artworks. I do not see scientific papers any different. --Jarekt (talk) 21:58, 17 June 2020 (UTC)
- Out of interest, we are just populating United States Census Bureau publications with a few thousand large-ish to extremely large documents. These are, to my mind, dull as ditch-water to look at, apart from the odd map, but might be very exciting for someone to run some analysis of the data and create charts to support a Wikipedia article. The issue for Commons is that it's still not very nice to browse a PDF on our website, and the only way to link to a specific page (like a map) is to use a thumbnail as the normal image syntax still misses a "page" parameter. Without some basic improvements to the reader interface for articles and books, an import of a million articles is highly likely to remain virtually unused and impenetrable. --Fæ (talk) 10:04, 19 June 2020 (UTC)
 Comment What is the function of books and scientific papers being on scope in both Wikisource and Commons? Isn't that essentially the same as hosting articles on both Commons and Wikipedia, or pictures of lifeforms on both Commons and Wikispecies? --Pitke (talk) 11:52, 26 June 2020 (UTC)
Comment What is the function of books and scientific papers being on scope in both Wikisource and Commons? Isn't that essentially the same as hosting articles on both Commons and Wikipedia, or pictures of lifeforms on both Commons and Wikispecies? --Pitke (talk) 11:52, 26 June 2020 (UTC)
- Can you even upload images to Wikispecies? We need scans of books on Wikisource in order to transcribe them. In some cases, they're used on multiple Wikisources for different languages; in others, they're the source work for various extracted images that might see use on Wikipedia, Wikispecies or Wiktionary as well as Wikisource. In others, they're files that are going to be used on one Wikisource; is there any reason that Wikisources should not upload their files to Commons just like all the other projects do?--Prosfilaes (talk) 23:33, 26 June 2020 (UTC)
- A PDF of a digital document that provides nothing beyond a text file would be an example. -Mys_721tx (talk) 06:52, 27 June 2020 (UTC)
- An example of what? I ask again, is there any reason that Wikisources should not upload their files to Commons just like all the other projects do?--Prosfilaes (talk) 21:39, 27 June 2020 (UTC)
- One type of disallowed PDF files given by COM:SCOPE is those whose "... content is essentially raw text; such files are not considered media files. Note that scans of existing books, reports, newspapers etc of historic or other external significance are not excluded on this ground, even if they contain no images."-Mys_721tx (talk) 01:07, 30 June 2020 (UTC)
- @Mys 721tx: If that was intended as a rejoinder to Prosfilaes' question, it actually is rather the opposite: that indicates that "scans of existing books, reports, newspapers etc of historic or other external significance" are in scope. - Jmabel ! talk 02:43, 30 June 2020 (UTC)
- I fail to see the contradiction. Book scan? Yes. Government paperwork? Probably. Literally a plain text file converted to a PDF? No. -Mys_721tx (talk) 02:56, 30 June 2020 (UTC)
- As an illustration of liminal cases, we have just uploaded the delightful File:Administrative Notes (IA 568391 02 07).pdf.
- This is only just more than a plain text file, as it was manually typed up in 1981 and presumably photocopied for wide circulation. As a series, these brief administrative notes would give insight in to library operations in pre-digital days, when microfiches were the best alternative to paper prints.
- If someone were to feed these in to OCR and create texts with the same layout, they would be more readable and more searchable, however one can still make the case that the look of the original, including the unique physical way the typewriter has not made perfect impressions, should not be lost or made hard to discover. --Fæ (talk) 09:21, 1 July 2020 (UTC)
- What I meant by plain text file is in its computer science sense, an array of human readable characters. They can be hosted directly on Wikisource barring any licensing issue. Converting them to PDF via text2pdf, Microsoft Word, or any other program adds nothing to its presentation. -Mys_721tx (talk) 18:46, 1 July 2020 (UTC)
- I fail to see the contradiction. Book scan? Yes. Government paperwork? Probably. Literally a plain text file converted to a PDF? No. -Mys_721tx (talk) 02:56, 30 June 2020 (UTC)
- @Mys 721tx: If that was intended as a rejoinder to Prosfilaes' question, it actually is rather the opposite: that indicates that "scans of existing books, reports, newspapers etc of historic or other external significance" are in scope. - Jmabel ! talk 02:43, 30 June 2020 (UTC)
- One type of disallowed PDF files given by COM:SCOPE is those whose "... content is essentially raw text; such files are not considered media files. Note that scans of existing books, reports, newspapers etc of historic or other external significance are not excluded on this ground, even if they contain no images."-Mys_721tx (talk) 01:07, 30 June 2020 (UTC)
- An example of what? I ask again, is there any reason that Wikisources should not upload their files to Commons just like all the other projects do?--Prosfilaes (talk) 21:39, 27 June 2020 (UTC)
- A PDF of a digital document that provides nothing beyond a text file would be an example. -Mys_721tx (talk) 06:52, 27 June 2020 (UTC)
- Can you even upload images to Wikispecies? We need scans of books on Wikisource in order to transcribe them. In some cases, they're used on multiple Wikisources for different languages; in others, they're the source work for various extracted images that might see use on Wikipedia, Wikispecies or Wiktionary as well as Wikisource. In others, they're files that are going to be used on one Wikisource; is there any reason that Wikisources should not upload their files to Commons just like all the other projects do?--Prosfilaes (talk) 23:33, 26 June 2020 (UTC)
I notice that this category has many thousands of PDF files, apparently whole books. Do they belong in Commons, or is Wikisource a better place for them? Jim.henderson (talk) 18:34, 25 June 2020 (UTC)
- See Commons:Project scope#Allowable reasons for PDF and DjVu formats. --Fæ (talk) 18:50, 25 June 2020 (UTC)
- Wikisource makes an digital copy of the text, often using a process called OCR, followed by manual cleanup of errors. In most wikisources this proccess starts with uploading the original file to commons, so the files should remain here.--Snaevar (talk) 23:25, 1 July 2020 (UTC)
Looking for a practical titleblacklist fix for perfectly good batch upload projects
My many batch upload projects have been running on Commons for many years. There's one very specific and very bad thorn in my side that wastes huge amounts of volunteer time, and for which there is no technical fix apart from playing around for every unique upload project trying to juggle official archive supplied titles into something that might pass the ever changing and ever increasing burden of the titleblacklist.
In practice, I simply don't bother, and many thousands of public domain images are missing from Commons, regardless of individual educational value. The balance between endless debugging and spending valuable volunteer time on the next project instead, just works out that way.
Here's an example from a few minutes ago:
APIError: titleblacklist-forbidden: The title "File:Joannis Marianae Hispani, e Societate Jesu, De rege et regis institutione libri III - ad Philippum III Hispaniae regem catholicum. Eiusdem De ponderibus & mensuris liber (IA joannismarianaeh00mari).pdf" has been banned from creation. It matches the following blacklist entry: " .*(richero|marian).*(maria|richero).*"
Ref: https://archive.org/details/joannismarianaeh00mari
Clearly when the Internet archive unique ID matches a proper name in the official title of a 17th Century public domain book is a reason to effectively permanently ban uploads of the work, there is something seriously wrong with the way titles are blacklisted, and something seriously wrong with the fact that batch uploaders like myself cannot get an exemption flag.
Thoughts about what should change, or do I walk on again, accepting that due to local design flaws, Commons will never have these works and Commons can never magically expect to have enough programming resources to keep fixing work-arounds because nobody can be allowed to have a positive exemption for the "titleblacklist"? Thanks --Fæ (talk) 14:11, 30 June 2020 (UTC)
- Addendum same goes for the spamblacklist, which is also stopping the upload of the various randomly used short-urls that curators frequently use in their archive descriptions, see recent problems. --Fæ (talk) 15:58, 30 June 2020 (UTC)
- For starters, I'll make a strong guess that should be two distinct blacklist entries: " .*richero.*maria.*" and " .*marian.*richero).*". (I'd also guess that the leading blank is an error.) But, yes, there really ought to be an exemption flag. - Jmabel ! talk 15:41, 30 June 2020 (UTC)
- I would support granting Commons:Template editor to users who regularly need to override the blacklist, even if they do not actually edit templates. -- King of ♥ ♦ ♣ ♠ 16:14, 30 June 2020 (UTC)
- That would grant tboverride but is there a group that does the spam exemptions on contents? Seems that one could request the specific flags, or bundle them in a specific new group. --Fæ (talk) 16:23, 30 June 2020 (UTC)
- I think tboverride is sufficient to cover everything, as I don't see any other right in Special:ListGroupRights that serves to allow overriding a blacklist. On the English Wikipedia, there is precedent for granting unnecessary permissions to people unlikely to abuse them when actual technical implementation of the correct permission set is months or years away. For example, TonyBallioni was granted intadmin to view deleted JS/CSS pages (as part of his anti-sockpuppetry work) even though the right exists primarily for people who edit such pages, because a bug currently prevents regular admins from doing so. -- King of ♥ ♦ ♣ ♠ 16:42, 30 June 2020 (UTC)
- That would grant tboverride but is there a group that does the spam exemptions on contents? Seems that one could request the specific flags, or bundle them in a specific new group. --Fæ (talk) 16:23, 30 June 2020 (UTC)
- This does look like a pragmatic thing to try. Thanks for the suggestion. Added at Commons:Requests for rights. --Fæ (talk) 16:55, 30 June 2020 (UTC)
 Not done both are on the global blacklists at meta, so you'll need to post there. meta:Talk:Title_blacklist meta:Talk:Spam_blacklist.--BevinKacon (talk) 16:17, 30 June 2020 (UTC)
Not done both are on the global blacklists at meta, so you'll need to post there. meta:Talk:Title_blacklist meta:Talk:Spam_blacklist.--BevinKacon (talk) 16:17, 30 June 2020 (UTC)
- @BevinKacon: Global blacklists do not prevent people with the right local permissions from editing past them. -- King of ♥ ♦ ♣ ♠ 16:20, 30 June 2020 (UTC)
- Yes, those discussion pages are about list contents, not user groups. --Fæ (talk) 16:23, 30 June 2020 (UTC)
- @BevinKacon: What purpose do you think the garish {{Nd}} template serves, here? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 10:40, 1 July 2020 (UTC)
- Can the short youtube link just be replaced with the full version before upload?--BevinKacon (talk) 16:39, 30 June 2020 (UTC)
- There's lots that can be done, and I have done such fixes in the past by parsing out urls and sniffing the redirects. However I'm not a spammer, and if the official metadata written by curators elsewhere being used to create the texts use these shorturls, all the extra processing and volunteer programming time spend working out how to get around an ever evolving spamblacklist just seems, wasteful, when it could be spend on sorting out more content. Keep in mind this isn't just "tu.be" it's also all other other trapped forms of shorturl and whatever other unexplained regexes get added. --Fæ (talk) 16:47, 30 June 2020 (UTC)
- It seems that you can include blocked URLs as long as you put them in
<includeonly>...</includeonly>tags: Special:Diff/429954071. So you might be able to work around the spam blacklist by putting the URL in a template. The template might have to be created after you transclude it on the file information page.
- Sorry for spamming the blacklist log a bit while testing stuff. --Stefan2 (talk) 19:55, 30 June 2020 (UTC)
- Am I right in thinking that, if selected users are allowed to upload blacklisted URLs, then other users would not be able to save (unrelated) edits to the affected pages? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 10:40, 1 July 2020 (UTC)
Category needs cleanup template
Do you think we need a "Category needs cleanup" template? SpinnerLaserz (talk) 19:32, 30 June 2020 (UTC)
- @SpinnerLaserz: Could you please be more specific about the problem for which you are proposing a solution? - Jmabel ! talk 01:08, 1 July 2020 (UTC)
- Some of the categories have pictures that are not the focus (e.g. A house picture that incidentally contains a statue). SpinnerLaserz (talk) 01:25, 1 July 2020 (UTC)
- @SpinnerLaserz: It's common and accepted for images to be categorized by depicted things that are not necessarily the focus of the picture. Opinions probably vary on how prominent something needs to be to be used for categorization; there is no firm rule that would be strong enough to back such a template. – BMacZero (🗩) 19:01, 1 July 2020 (UTC)
- If a category is becoming overwhelmed with these, then in may be time for a subcat such as Category:Remote views of the Space Needle or Category:Alaska-Yukon-Pacific Exposition logo (incidental). - Jmabel ! talk 19:41, 1 July 2020 (UTC)
- @SpinnerLaserz: It's common and accepted for images to be categorized by depicted things that are not necessarily the focus of the picture. Opinions probably vary on how prominent something needs to be to be used for categorization; there is no firm rule that would be strong enough to back such a template. – BMacZero (🗩) 19:01, 1 July 2020 (UTC)
Expectation of EXIF
Is there a page documenting the *expectation* of EXIF data in images? I know people often have their uploads questioned if they are without EXIF data, but can't find clear documentation of that requirement. Asaf (WMF) (talk) 11:14, 28 June 2020 (UTC)
- Hi Asaf, there's no strict requirement, only Commons:Image_guidelines#Guidelines. It's more of a preference, but does get mentioned at FPC, see special:search/exif prefix:Commons:Featured_picture_candidates.--BevinKacon (talk) 11:38, 28 June 2020 (UTC)
- Thank you! While I know it's not strictly required, I find it mentioned not only at FPC, but also at deletion discussions. I understand sometimes the lack of EXIF means the image is indeed not the uploader's own, but there are also cases where one would legitimately want to wipe the EXIF data, e.g. if one took a photo of a household object in one's home, to illustrate an article, but isn't interested in forever exposing the coordinates of that home. So there is no actual policy about this? The guidelines you link to only refer to EXIF in the context of the color space technical information, not as indicator of the provenance of the image. Asaf (WMF) (talk) 12:06, 28 June 2020 (UTC)
- We will change or remove any privacy related exif data at the request of the uploader to avoid file deletion. I removed serial number from File:Drone shot of bra.jpg. Not aware of any policy or guideline, only instructional pages.--BevinKacon (talk) 12:18, 28 June 2020 (UTC)
- (ec) Just 0.02 but to say that EXIF is only an indicator of things. Not only can it be wiped it can be falsified... For me it is one of many aspects to be looked at. Equally a hard one to make policy on (not least of which people "use" policy in whatever way they wish
 --Herby talk thyme 12:21, 28 June 2020 (UTC)
--Herby talk thyme 12:21, 28 June 2020 (UTC)
- I have also experienced that certain programs eliminate the EXIF data. For example when image stitching to a panorama. Wouter (talk) 12:33, 28 June 2020 (UTC)
- As with others, this is a balance of probability issue, per "significant doubt" in COM:PRP.
- Were you to upload a photo with EXIF (apparently) cut off, the file would be well above "significant doubt" in a way that a newbie account might have problems with.
- EXIF tampering is a real problem, we have seen vandals deliberately cloning EXIF data on to files lifted from photography websites, or Facebook. As this has been to fake copyright releases, this is taken as serious block-able disruption.
- We have had plenty of cases where users want their personal names or GPS data removed from the EXIF already uploaded, and it's not too hard to arrange for a bot to selectively remove specific EXIF tags as needed. This does not mean that all the rest of the EXIF needs to go, and as a norm, we can probably recommend that where privacy issues occur we want folks to not blank the whole EXIF, but retain as much as they feel is relevant to the file without revealing unnecessary detail about the photographer. In particular it should not be a requirement for an uploader to release original EXIF data if they are not comfortable with doing that.
- This is a question that comes up regularly, and it would be handy if one of the project guidelines had a summary to point newbies and disputes towards.
- Corollary It would be of benefit if the project had a principle that highly technical research on mass EXIF data should be avoided on the public wiki unless there are no potential privacy issues that might cause harm to the photographer. There can be accidental tracking data left in a succession of photographs that could show that someone was, say, at a political protest, or in countries that the police in their home intelligence services would find problematic if the pattern of data is laid out explicitly. I have in mind one contributor living in China using multiple harmless sock accounts, and their anonymity should not be compromised via EXIF GPS tags and lens codes, just because someone likes tracking sock accounts and fancies experimenting with EXIF mapping. --Fæ (talk) 12:59, 28 June 2020 (UTC)
- Thank you. Yes, as you say, "This is a question that comes up regularly, and it would be handy if one of the project guidelines had a summary to point newbies and disputes towards." This is precisely what I was looking for (in order to refer people to it). I don't feel I am sufficiently active in Commons as a volunteer to propose guideline changes, but it would be great if some of you reading this who are could propose, discuss, and (if there are no strong objections) enact such a change, so that there is something to point to henceforth. Cheers! Asaf (WMF) (talk) 15:27, 28 June 2020 (UTC)
- Thank you! While I know it's not strictly required, I find it mentioned not only at FPC, but also at deletion discussions. I understand sometimes the lack of EXIF means the image is indeed not the uploader's own, but there are also cases where one would legitimately want to wipe the EXIF data, e.g. if one took a photo of a household object in one's home, to illustrate an article, but isn't interested in forever exposing the coordinates of that home. So there is no actual policy about this? The guidelines you link to only refer to EXIF in the context of the color space technical information, not as indicator of the provenance of the image. Asaf (WMF) (talk) 12:06, 28 June 2020 (UTC)
{kind=link}
Editing exif to upload stolen images can go undetected for years, see Commons:Deletion requests/Files uploaded by Marianne Casamance, which involved a user photoshopping files and applying fake camera data to 10,000+ files under multiple accounts.--BevinKacon (talk) 13:30, 28 June 2020 (UTC)
It'd be great if the Upload Wizard offered a choice to remove specific EXIF data like location, serial numbers, and makernotes. (I've tried some free tools that claimed to remove location but didn't, so am sympathetic to those who would want to wipe the whole lot to be sure.) I imagine this may have been proposed or requested before? Pelagic (talk) 15:30, 28 June 2020 (UTC)
- Having only delved into EXIF editing modules briefly, the issue with creating a tool is the variety of interpretations that exist for different camera manufacturers, and more recently, mobile phone camera apps. Though there are standards for EXIF data, there are also unspecified extra tags used by photoshop and mobile apps that hold all sorts of edit-time tags, or even extra tracking info like unique serial numbers of software.
- Basic tag stripping could be added as a gadget, but if that only handles stuff that would be displayed on image pages, that would be limited to standard EXIF tags, ignore non-standard ones, and probably have to ignore other header data like IPTC. It could be more pragmatic and useful to warn users to review their data themselves before upload, perhaps by providing a link to a WMF hosted header examination tool similar to Jeffrey's excellent version http://exif.regex.info/exif.cgi, and pointing to a guideline pages with example free header data editing tools. --Fæ (talk) 10:36, 29 June 2020 (UTC)
@Asaf (WMF): I think it's important to know that there are many perfectly legitimate reasons for not having Exif data in an image; you might find this discussion interesting where I presented an example by dusting off a very old digital camera :-). As I wrote there, "I often think, when processing deletion requests, that people nowadays tend to suspect copyright violations too quickly if an image is rather small and/or doesn't have EXIF data." If we were to create a summary as suggested by Fæ, I think it should be something along the lines of "missing Exif data and/or small size can be reasonable grounds for suspicion, but shouldn't be used as the sole grounds for deletion", and that the context is important. Gestumblindi (talk) 21:51, 2 July 2020 (UTC)
- Agreed! So, can we move towards some written guideline around it? I think status quo, where it is both unwritten/invisible and used (too?) frequently to propose deletion, is sub-optimal. Asaf (WMF) (talk) 23:09, 2 July 2020 (UTC)
- I suppose that we could expand Commons:Exif, which is currently more about the technical side of Exif data, with a section on the "expectation of Exif" and its limitations. I think I will give it a try soon... Gestumblindi (talk) 12:15, 4 July 2020 (UTC)
3,000,000 Wikidata Infoboxes in Commons categories
Just to note that we now have over 3 million Commons categories using {{Wikidata Infobox}} - see Category:Uses of Wikidata Infobox! Thanks. Mike Peel (talk) 20:20, 19 June 2020 (UTC)
- Good job! 4nn1l2 (talk) 20:23, 19 June 2020 (UTC)
- Great job to Mike Peel and everyone else who add them, these infoboxes are really handy. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:05, 20 June 2020 (UTC)
- I noticed too Mike. Nice milestone. It helps to improve Commons and Wikidata. A lot of categories are deduped, birth day categories fixed. etc Rudolphous (talk) 06:38, 24 June 2020 (UTC)
- Useful and a nice precedent. Blue Rasberry (talk) 15:19, 30 June 2020 (UTC)
- @Mike Peel: Thank you very much. It is certainly possible to improve this tool (and its source data) in many ways, but from the beginning it is a very practical, useful and functional tool (and its bugs are usually not fatal). --ŠJů (talk) 22:26, 6 July 2020 (UTC)
- Awesome! Chicdat (talk · contribs)... on Wikipedia 12:23, 13 July 2020 (UTC)
Is there a tool to expand a specific category tree?

something similar to this, so that i can see the entire cat tree.--RZuo (talk) 19:16, 29 June 2020 (UTC)
- Since category inclusions can be circular, you can't really always do the "entire tree". - Jmabel ! talk 00:06, 30 June 2020 (UTC)
- The tool can easily tackle this problem, either by setting a max depth to expand, or by remembering what categories have been expanded so that they wont be expanded again.
- Is there such a tool?--RZuo (talk) 11:03, 8 July 2020 (UTC)
- @RZuo: I use the categorytree pseudoelement enabled by m:Extension:CategoryTree, for instance to show users needing help I use wikitext "<categorytree mode=all showcount=yes>User needing help" to show all the users needing help, with counts: User needing help - ar (empty)User needing help - bn (empty)User needing help - de (empty)User needing help - el (empty)User needing help - es (empty)User needing help - fa (empty)User needing help - fr (empty)User needing help - he (empty)User needing help - id (empty)User needing help - it (empty)User needing help - ja (empty)User needing help - ms (empty)User needing help - nl (empty)User needing help - pl (empty)User needing help - ru (empty)User needing help - sv (empty)
- Click the dark triangles to expand/contract. — Jeff G. ツ please ping or talk to me 18:24, 8 July 2020 (UTC)
- I know this tool. It's no different from what you have on a cat page. It expands subcats click by click. A great tool to expand all at the same level at once, or all subcats at all levels at once, would be better.--RZuo (talk) 20:10, 14 July 2020 (UTC)
- @RZuo: I use the categorytree pseudoelement enabled by m:Extension:CategoryTree, for instance to show users needing help I use wikitext "<categorytree mode=all showcount=yes>User needing help" to show all the users needing help, with counts:
{kind=link}
{kind=link}